Proxies keep your scrapers from getting blocked by masking your IP, spreading requests across many addresses, and letting you reach geo-restricted content. But "proxy" covers several very different things, and picking the wrong type either wastes money or gets you blocked anyway. This guide breaks down the main types of proxies for web scraping, residential, datacenter, mobile, and specialized, with the trade-offs, code examples, and rotation practices for each so you can match the proxy to the target.
Short Summary
- Understanding proxies for web scraping is essential, as they enable users to mask their IP addresses and access geo-blocked content.
- Different types of proxies offer varying levels of anonymity and performance. Factors such as size of the IP pool, geolocation options, response time & level of anonymity should be considered when selecting a proxy provider.
- Best practices like proxy rotation, pool management, and effective error handling are necessary for successful web scraping activity.
Understanding Proxies for Web Scraping

Proxies are an indispensable component of web scraping, acting as intermediaries between users and the internet. By masking users' IP addresses, proxies enable access to websites while maintaining anonymity. This is particularly important for web scraping, as it enables users to bypass website restrictions, ensure privacy, and access geo-restricted content without detection.
There are several types of proxies commonly used in web scraping, including data center proxies, residential proxies, mobile proxies, and specialized proxies. Each type of proxy has its advantages and drawbacks, which we will explore in detail to help you choose the right one for your web scraping project.
But first, let's dive deeper into the world of proxy servers and proxy services.
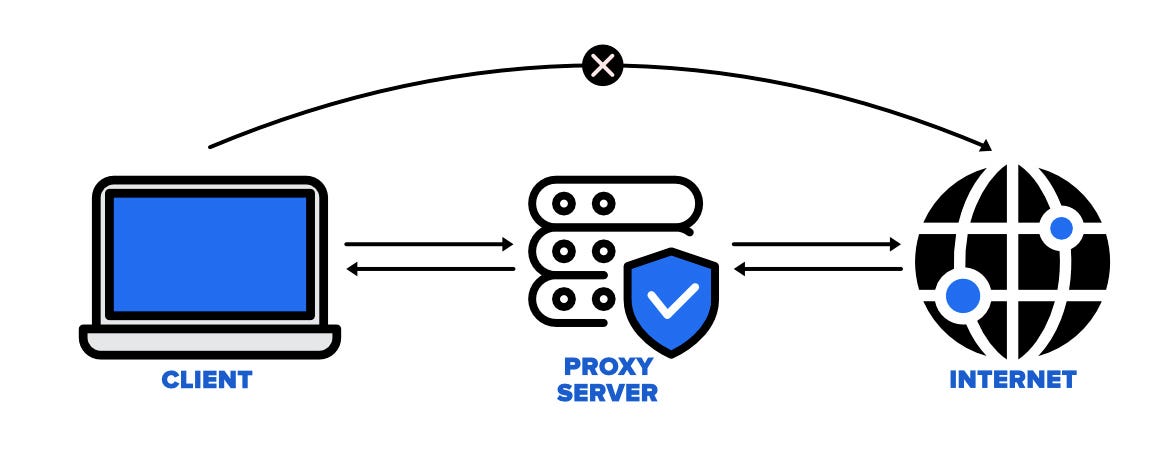
What is a Proxy Server?
A proxy server acts as a go-between for users and the internet, allowing access to websites while concealing IP addresses and preserving privacy. This intermediary role ensures that users' identities remain hidden, which is crucial for web scraping as it helps avoid IP bans and maintain anonymity.
When you use a proxy server, your web scraping requests first go to the proxy server, which then forwards them to the target website. The website sees the proxy's IP address instead of your real IP address, providing anonymity and protection from potential blocking.
How Proxies Work in Web Scraping:
# Without proxy - direct connection
import requests
# Your real IP is exposed to the target website
response = requests.get('https://target-website.com')
# With proxy - connection through intermediary
proxies = {
'http': 'http://proxy-server.com:8080',
'https': 'http://proxy-server.com:8080'
}
# Target website sees proxy IP, not your real IP
response = requests.get('https://target-website.com', proxies=proxies)While free proxies may be available, they often come with limitations and may not be suitable for professional web scraping purposes. It's essential to choose a reliable proxy provider that offers residential and datacenter proxies tailored for web scraping, ensuring a seamless and efficient scraping experience without the risk of detection or IP blocking.
Importance of Proxies in Web Scraping
Proxies play a crucial role in web scraping by helping users achieve several key objectives:
1. Avoiding IP Bans and Rate Limiting
- Distribute requests across multiple IP addresses
- Prevent websites from detecting automated behavior
- Maintain consistent access to target websites
2. Geographic Content Access
- Access geo-restricted content from different regions
- Scrape localized search results and pricing
- Bypass country-specific blocking measures
3. Scalability and Performance
- Enable concurrent scraping from multiple IPs
- Reduce bottlenecks caused by single IP limitations
- Improve overall scraping throughput
4. Anonymity and Privacy
- Hide your real IP address and location
- Protect your identity during data collection
- Comply with privacy and security requirements
Types of Proxies Used in Web Scraping
Understanding the various types of proxies used in web scraping is crucial for selecting the right one for your project. In the following sections, we will discuss data center proxies, residential proxies, mobile proxies, and specialized proxies, exploring their features, advantages, and limitations to help you make an informed decision.
The choice between proxy types depends on your specific requirements: budget constraints, target websites, required anonymity level, and scraping scale. Let's examine each type in detail.
Data Center Proxies
Data center proxies are commercially assigned to servers hosted in data centers and are not associated with internet service providers (ISPs) or real residential locations. These proxies are created in cloud environments and offer the fastest connection speeds available for web scraping operations.
Key Characteristics:
- Speed: Fastest proxy type with low latency (typically <50ms)
- Cost: Most affordable option, often $1-3 per IP per month
- Pool Size: Large IP pools available (thousands to millions)
- Detection Risk: Higher chance of being detected as non-residential traffic
Advantages:
- High-speed connections ideal for large-scale scraping
- Excellent uptime and reliability (99.9%+)
- Cost-effective for bulk operations
- Easy to set up and configure
- Dedicated IPs available for consistent identity
Disadvantages:
- Easier to detect and block by anti-bot systems
- Shared subnets can lead to collective IP bans
- Less suitable for websites with strict bot detection
- May require frequent IP rotation
Best Use Cases:
- API scraping and data extraction
- Price monitoring at scale
- SEO rank tracking
- Non-sensitive web scraping tasks
- High-volume data collection
# Example: Using datacenter proxies with Python requests
import requests
import random
import time
class DatacenterProxyManager:
def __init__(self, proxy_list):
self.proxy_list = proxy_list
self.current_index = 0
def get_next_proxy(self):
proxy = self.proxy_list[self.current_index]
self.current_index = (self.current_index + 1) % len(self.proxy_list)
return proxy
def scrape_with_rotation(self, urls):
results = []
for i, url in enumerate(urls):
proxy = self.get_next_proxy()
proxies = {
'http': proxy,
'https': proxy
}
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8'
}
try:
response = requests.get(url, proxies=proxies, headers=headers, timeout=10)
if response.status_code == 200:
results.append({
'url': url,
'content': response.text,
'proxy_used': proxy
})
# Rate limiting - be respectful
time.sleep(random.uniform(1, 3))
except requests.exceptions.RequestException as e:
print(f"Error with proxy {proxy}: {e}")
return results
# Usage
datacenter_proxies = [
"http://user:pass@dc-proxy1.com:8080",
"http://user:pass@dc-proxy2.com:8080",
"http://user:pass@dc-proxy3.com:8080"
]
proxy_manager = DatacenterProxyManager(datacenter_proxies)
urls_to_scrape = ["https://example1.com", "https://example2.com"]
results = proxy_manager.scrape_with_rotation(urls_to_scrape)Residential Proxies
Residential proxies use IP addresses assigned by Internet Service Providers (ISPs) to real residential locations. These proxies route traffic through actual devices in homes, making them appear as legitimate user traffic to target websites.
Key Characteristics:
- Authenticity: Real IP addresses from ISPs assigned to homes
- Cost: More expensive, typically $5-15 per GB of traffic
- Speed: Slower than datacenter proxies due to residential infrastructure
- Detection Rate: Extremely low, appear as regular users
Advantages:
- Highest level of anonymity and legitimacy
- Virtually undetectable by anti-bot systems
- Can access geo-restricted content effectively
- Lower ban rates and higher success rates
- Excellent for scraping social media and e-commerce sites
Disadvantages:
- More expensive than datacenter proxies
- Slower connection speeds (100-500ms latency)
- Limited bandwidth in some cases
- Ethical considerations regarding user consent
- Less predictable performance
Best Use Cases:
- Social media scraping (Instagram, Facebook, Twitter)
- E-commerce data collection (Amazon, eBay, Shopify)
- Ad verification and competitor analysis
- Market research and brand monitoring
- Accessing geo-blocked content
- Sneaker copping and limited product purchases
// Example: Using residential proxies with Node.js and Puppeteer
const puppeteer = require('puppeteer');
class ResidentialProxyScraper {
constructor(proxyConfig) {
this.proxyConfig = proxyConfig;
}
async scrapeWithResidentialProxy(url, options = {}) {
const browser = await puppeteer.launch({
args: [
`--proxy-server=${this.proxyConfig.protocol}://${this.proxyConfig.host}:${this.proxyConfig.port}`,
'--no-sandbox',
'--disable-setuid-sandbox',
'--disable-blink-features=AutomationControlled'
],
headless: options.headless !== false
});
const page = await browser.newPage();
// Authenticate with proxy credentials
if (this.proxyConfig.username && this.proxyConfig.password) {
await page.authenticate({
username: this.proxyConfig.username,
password: this.proxyConfig.password
});
}
// Set realistic headers and viewport
await page.setUserAgent('Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36');
await page.setViewport({ width: 1366, height: 768 });
// Remove automation indicators
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined,
});
});
try {
// Navigate with realistic timing
await page.goto(url, {
waitUntil: 'networkidle2',
timeout: 30000
});
// Simulate human behavior
await page.mouse.move(100, 100);
await new Promise(resolve => setTimeout(resolve, 1000));
const content = await page.content();
const title = await page.title();
await browser.close();
return {
success: true,
content,
title,
url
};
} catch (error) {
console.error('Scraping failed:', error);
await browser.close();
return {
success: false,
error: error.message,
url
};
}
}
}
// Usage
const proxyConfig = {
protocol: 'http',
host: 'residential-proxy.com',
port: 8080,
username: 'your-username',
password: 'your-password'
};
const scraper = new ResidentialProxyScraper(proxyConfig);
async function scrapeMultiplePages() {
const urls = [
'https://example-ecommerce.com/products',
'https://social-media-site.com/trending'
];
for (const url of urls) {
const result = await scraper.scrapeWithResidentialProxy(url);
console.log(`Scraped ${url}:`, result.success ? 'Success' : 'Failed');
// Respectful delay between requests
await new Promise(resolve => setTimeout(resolve, 2000));
}
}
scrapeMultiplePages();Mobile Proxies
Mobile proxies route traffic through mobile carrier networks (3G/4G/5G), using IP addresses assigned to mobile devices. These proxies provide the highest level of trust since they use the same infrastructure as regular mobile users.
Key Characteristics:
- Network: 3G/4G/5G cellular networks
- Cost: Most expensive option, $20-100+ per IP per month
- Trust Level: Highest trust rating from websites
- IP Rotation: Automatic IP changes when mobile towers switch
Advantages:
- Extremely high success rates (95%+ for most sites)
- Lowest detection and ban rates
- Automatic IP rotation through carrier networks
- Ideal for social media and mobile-first platforms
- Can bypass the most sophisticated anti-bot systems
- Geographic distribution through cellular towers
Disadvantages:
- Most expensive proxy type
- Limited bandwidth and data allowances
- Variable connection speeds (100-1000ms latency)
- Fewer available IP addresses
- Higher complexity in setup and management
Best Use Cases:
- Social media automation and scraping
- Mobile app testing and data collection
- Sneaker bots and limited product purchasing
- Ad verification on mobile platforms
- Gaming and entertainment platform access
- High-value, low-volume scraping tasks
# Example: Using mobile proxies with proper rotation and error handling
import requests
import time
from itertools import cycle
import logging
class MobileProxyRotator:
def __init__(self, mobile_proxies):
self.proxy_cycle = cycle(mobile_proxies)
self.current_proxy = None
self.proxy_stats = {proxy['id']: {'requests': 0, 'failures': 0} for proxy in mobile_proxies}
def get_next_proxy(self):
self.current_proxy = next(self.proxy_cycle)
return self.current_proxy
def make_mobile_request(self, url, headers=None, max_retries=3):
"""Make request optimized for mobile proxies"""
default_mobile_headers = {
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 17_0 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Mobile/15E148 Safari/604.1',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate, br',
'DNT': '1',
'Connection': 'keep-alive',
'Upgrade-Insecure-Requests': '1'
}
if headers:
default_mobile_headers.update(headers)
for attempt in range(max_retries):
proxy = self.get_next_proxy()
proxy_url = f"http://{proxy['username']}:{proxy['password']}@{proxy['host']}:{proxy['port']}"
proxies = {
'http': proxy_url,
'https': proxy_url
}
try:
# Mobile networks can be slower, increase timeout
response = requests.get(
url,
proxies=proxies,
headers=default_mobile_headers,
timeout=45,
verify=False # Some mobile proxies have SSL issues
)
self.proxy_stats[proxy['id']]['requests'] += 1
if response.status_code == 200:
logging.info(f"Successful request via mobile proxy {proxy['id']}")
return response
elif response.status_code in [403, 429]:
logging.warning(f"Rate limited on proxy {proxy['id']}")
self.proxy_stats[proxy['id']]['failures'] += 1
# Switch to different proxy immediately
continue
except requests.exceptions.RequestException as e:
logging.error(f"Request failed with mobile proxy {proxy['id']}: {e}")
self.proxy_stats[proxy['id']]['failures'] += 1
# Mobile networks can be unstable, longer delay
time.sleep(5)
return None
def get_proxy_stats(self):
"""Get statistics for all proxies"""
return self.proxy_stats
# Usage example with mobile proxy configuration
mobile_proxies = [
{
"id": "mobile_1",
"host": "mobile1.proxy.com",
"port": 8080,
"username": "user1",
"password": "pass1",
"carrier": "verizon",
"location": "new_york"
},
{
"id": "mobile_2",
"host": "mobile2.proxy.com",
"port": 8080,
"username": "user2",
"password": "pass2",
"carrier": "att",
"location": "california"
}
]
# Social media scraping with mobile proxies
class SocialMediaScraper:
def __init__(self, mobile_proxies):
self.rotator = MobileProxyRotator(mobile_proxies)
def scrape_instagram_profile(self, username):
url = f"https://www.instagram.com/{username}/"
# Instagram-specific headers
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none'
}
response = self.rotator.make_mobile_request(url, headers)
if response:
# Parse profile data here
return {
'username': username,
'content': response.text,
'status': 'success'
}
else:
return {
'username': username,
'status': 'failed'
}
# Initialize and use
scraper = SocialMediaScraper(mobile_proxies)
profile_data = scraper.scrape_instagram_profile('example_user')
print(f"Scraping result: {profile_data['status']}")
# Check proxy performance
stats = scraper.rotator.get_proxy_stats()
for proxy_id, stat in stats.items():
success_rate = ((stat['requests'] - stat['failures']) / stat['requests'] * 100) if stat['requests'] > 0 else 0
print(f"Proxy {proxy_id}: {success_rate:.1f}% success rate")Specialized Proxies
Specialized proxies are purpose-built solutions designed specifically for web scraping and automation tasks. These proxies combine the best features of different proxy types with additional optimization for specific use cases.
Types of Specialized Proxies:
1. Rotating Proxies
- Automatic IP rotation at set intervals
- Built-in session management
- Load balancing across multiple endpoints
2. ISP Proxies (Static Residential)
- Hosted in data centers but use residential IP ranges
- Combine speed of datacenter with legitimacy of residential
- Perfect balance of performance and anonymity
3. Dedicated Proxies
- Exclusive use of specific IP addresses
- Consistent identity for session-based scraping
- Premium pricing but guaranteed availability
Key Features:
- Smart Rotation: Automatic IP switching based on rules
- Geo-targeting: Country and city-level location selection
- Protocol Support: HTTP, HTTPS, SOCKS4, SOCKS5
- Authentication: Username/password or IP whitelisting
- API Integration: RESTful APIs for proxy management
Advantages:
- Optimized specifically for web scraping
- Advanced features like sticky sessions
- Built-in retry mechanisms and error handling
- Comprehensive analytics and monitoring
- Technical support specialized in scraping
Best Use Cases:
- Large-scale data extraction projects
- Enterprise web scraping operations
- Complex multi-step scraping workflows
- High-frequency data collection
- Mission-critical scraping applications
# Example: Using specialized rotating proxy service with API
import requests
from datetime import datetime, timedelta
import json
class SpecializedProxyManager:
def __init__(self, api_endpoint, api_key):
self.api_endpoint = api_endpoint
self.api_key = api_key
self.session_cache = {}
def get_optimized_proxy(self, target_domain, requirements=None):
"""Get proxy optimized for specific domain and requirements"""
payload = {
'target_domain': target_domain,
'requirements': requirements or {},
'session_id': self._get_session_id(target_domain),
'format': 'json'
}
headers = {
'Authorization': f'Bearer {self.api_key}',
'Content-Type': 'application/json'
}
try:
response = requests.post(
f'{self.api_endpoint}/proxy/allocate',
json=payload,
headers=headers,
timeout=10
)
if response.status_code == 200:
return response.json()
else:
print(f"API Error: {response.status_code} - {response.text}")
return None
except requests.exceptions.RequestException as e:
print(f"API request failed: {e}")
return None
def _get_session_id(self, domain):
"""Generate or retrieve session ID for domain"""
if domain not in self.session_cache:
self.session_cache[domain] = f"session_{hash(domain)}_{int(datetime.now().timestamp())}"
return self.session_cache[domain]
def scrape_with_optimization(self, url, requirements=None):
"""Scrape URL with automatically optimized proxy"""
domain = self._extract_domain(url)
proxy_config = self.get_optimized_proxy(domain, requirements)
if not proxy_config:
return None
# Use the optimized proxy configuration
proxies = {
'http': proxy_config['proxy_url'],
'https': proxy_config['proxy_url']
}
# Use recommended headers from the service
headers = proxy_config.get('recommended_headers', {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
})
try:
response = requests.get(
url,
proxies=proxies,
headers=headers,
timeout=proxy_config.get('recommended_timeout', 30)
)
# Report success back to the service for optimization
self._report_result(proxy_config['allocation_id'], True, response.status_code)
return {
'success': True,
'content': response.text,
'status_code': response.status_code,
'proxy_used': proxy_config['proxy_info'],
'response_time': response.elapsed.total_seconds()
}
except requests.exceptions.RequestException as e:
# Report failure for service optimization
self._report_result(proxy_config['allocation_id'], False, 0)
return {
'success': False,
'error': str(e),
'proxy_used': proxy_config['proxy_info']
}
def _extract_domain(self, url):
"""Extract domain from URL"""
from urllib.parse import urlparse
return urlparse(url).netloc
def _report_result(self, allocation_id, success, status_code):
"""Report request result for proxy optimization"""
payload = {
'allocation_id': allocation_id,
'success': success,
'status_code': status_code,
'timestamp': datetime.utcnow().isoformat()
}
headers = {'Authorization': f'Bearer {self.api_key}'}
try:
requests.post(
f'{self.api_endpoint}/proxy/report',
json=payload,
headers=headers,
timeout=5
)
except:
pass # Don't fail scraping if reporting fails
# Advanced usage with requirements specification
class EnterpriseWebScraper:
def __init__(self, proxy_manager):
self.proxy_manager = proxy_manager
def scrape_ecommerce_data(self, product_urls):
"""Scrape e-commerce data with optimized settings"""
requirements = {
'anonymity_level': 'high',
'geo_location': 'US',
'proxy_type': 'residential',
'session_persistence': True,
'javascript_support': False
}
results = []
for url in product_urls:
print(f"Scraping {url}...")
result = self.proxy_manager.scrape_with_optimization(
url,
requirements=requirements
)
if result and result['success']:
# Parse product data
product_data = self._parse_product_data(result['content'])
results.append({
'url': url,
'data': product_data,
'metadata': {
'proxy_used': result['proxy_used'],
'response_time': result['response_time']
}
})
else:
print(f"Failed to scrape {url}: {result.get('error', 'Unknown error')}")
# Respectful delay
time.sleep(2)
return results
def _parse_product_data(self, html_content):
"""Parse product data from HTML"""
# Implement parsing logic here
return {'title': 'Example Product', 'price': '$99.99'}
# Usage
proxy_manager = SpecializedProxyManager(
'https://api.specialized-proxy.com/v1',
'your-api-key-here'
)
scraper = EnterpriseWebScraper(proxy_manager)
product_urls = [
'https://example-store.com/product/1',
'https://example-store.com/product/2'
]
results = scraper.scrape_ecommerce_data(product_urls)
print(f"Successfully scraped {len(results)} products")Choosing the Right Proxy for Your Web Scraping Project

Selecting the best proxy provider for your web scraping needs can be a daunting task, given the variety of options, features, and pricing plans available. To help you make an informed decision, we will discuss the factors to consider when choosing a proxy provider, as well as provide a comparison framework for evaluating different providers.
By understanding the key factors and comparing the features of different proxy providers, you can find the perfect proxy solution for your web scraping project, ensuring optimal performance, reliability, and anonymity.
Factors to Consider
Selecting the right proxy provider requires careful evaluation of multiple factors that directly impact your web scraping success:
1. IP Pool Size and Quality
- Pool Size: Larger pools (100K+ IPs) reduce the risk of IP exhaustion
- IP Freshness: Regular rotation and addition of new IPs
- Subnet Diversity: IPs spread across different subnets and ASNs
- Geo-Distribution: Global coverage for international scraping needs
2. Performance Metrics
- Response Time: Target <200ms for optimal performance
- Uptime: 99.5%+ availability for reliable operations
- Bandwidth: Sufficient data allowances for your scraping volume
- Concurrent Connections: Support for parallel scraping operations
3. Anonymity and Security
- Anonymity Level: Elite (transparent), anonymous, or transparent proxies
- IP Leak Protection: DNS and WebRTC leak prevention
- SSL Support: HTTPS compatibility for secure connections
- No-logs Policy: Provider doesn't store usage data
4. Technical Features
- Protocol Support: HTTP/HTTPS/SOCKS4/SOCKS5 compatibility
- Authentication Methods: Username/password or IP whitelisting
- API Access: Programmatic proxy management capabilities
- Session Control: Sticky sessions for multi-step operations
5. Pricing and Support
- Pricing Model: Pay-per-IP, pay-per-GB, or unlimited plans
- Scalability: Ability to upgrade as your needs grow
- Support Quality: Technical expertise and response times
- Trial Period: Risk-free testing opportunities
Proxy Selection Decision Matrix:
| Use Case | Recommended Proxy Type | Key Considerations | Budget Range |
| API Scraping | Datacenter | Speed, reliability, cost | $50-200/month |
| E-commerce Monitoring | Residential | Anonymity, success rate | $200-800/month |
| Social Media Scraping | Mobile | Trust score, detection avoidance | $500-2000/month |
| Enterprise Scraping | Specialized/ISP | Features, support, SLA | $1000-5000/month |
| Geo-specific Content | Residential | Location coverage | $300-1000/month |
# Proxy provider evaluation framework
import time
import statistics
import requests
from concurrent.futures import ThreadPoolExecutor
import json
class ProxyProviderEvaluator:
def __init__(self):
self.test_urls = [
'https://httpbin.org/ip',
'https://httpbin.org/headers',
'https://www.google.com',
'https://example.com'
]
def evaluate_provider(self, proxy_config, test_count=50):
"""Comprehensive evaluation of proxy provider"""
results = {
'speed_tests': [],
'success_rate': 0,
'anonymity_score': 0,
'geo_accuracy': 0,
'reliability_score': 0,
'concurrent_performance': 0
}
print(f"Evaluating proxy provider: {proxy_config.get('name', 'Unknown')}")
# Test 1: Speed and Success Rate
speed_results = self._test_speed_and_success(proxy_config, test_count)
results.update(speed_results)
# Test 2: Anonymity Level
anonymity_score = self._test_anonymity(proxy_config)
results['anonymity_score'] = anonymity_score
# Test 3: Geographic Accuracy
geo_score = self._test_geographic_accuracy(proxy_config)
results['geo_accuracy'] = geo_score
# Test 4: Concurrent Performance
concurrent_score = self._test_concurrent_performance(proxy_config)
results['concurrent_performance'] = concurrent_score
# Calculate overall score
results['overall_score'] = self._calculate_overall_score(results)
return results
def _test_speed_and_success(self, proxy_config, test_count):
"""Test proxy speed and success rate"""
speeds = []
successes = 0
for i in range(test_count):
start_time = time.time()
try:
response = requests.get(
'https://httpbin.org/ip',
proxies=proxy_config['proxies'],
headers=proxy_config.get('headers', {}),
timeout=30
)
if response.status_code == 200:
response_time = time.time() - start_time
speeds.append(response_time)
successes += 1
except requests.exceptions.RequestException:
pass
# Small delay between tests
time.sleep(0.5)
return {
'speed_tests': speeds,
'average_speed': statistics.mean(speeds) if speeds else 0,
'speed_std': statistics.stdev(speeds) if len(speeds) > 1 else 0,
'success_rate': (successes / test_count) * 100
}
def _test_anonymity(self, proxy_config):
"""Test anonymity level of proxy"""
try:
# Test if proxy hides real IP
response = requests.get(
'https://httpbin.org/headers',
proxies=proxy_config['proxies'],
timeout=30
)
if response.status_code == 200:
headers = response.json().get('headers', {})
# Check for proxy-revealing headers
anonymity_score = 100
proxy_headers = [
'X-Forwarded-For',
'X-Real-IP',
'Via',
'X-Proxy-ID'
]
for header in proxy_headers:
if header in headers:
anonymity_score -= 20
return max(0, anonymity_score)
except requests.exceptions.RequestException:
pass
return 0
def _test_geographic_accuracy(self, proxy_config):
"""Test geographic location accuracy"""
try:
# Use a geolocation service
response = requests.get(
'http://ip-api.com/json/',
proxies=proxy_config['proxies'],
timeout=30
)
if response.status_code == 200:
geo_data = response.json()
expected_country = proxy_config.get('expected_country')
if expected_country and geo_data.get('countryCode') == expected_country:
return 100
elif expected_country:
return 0
else:
return 50 # No expectation set
except requests.exceptions.RequestException:
pass
return 0
def _test_concurrent_performance(self, proxy_config, concurrent_requests=10):
"""Test performance under concurrent load"""
def make_request():
try:
start_time = time.time()
response = requests.get(
'https://httpbin.org/ip',
proxies=proxy_config['proxies'],
timeout=30
)
response_time = time.time() - start_time
return response.status_code == 200, response_time
except:
return False, 0
with ThreadPoolExecutor(max_workers=concurrent_requests) as executor:
futures = [executor.submit(make_request) for _ in range(concurrent_requests)]
results = [future.result() for future in futures]
successes = sum(1 for success, _ in results if success)
avg_time = statistics.mean([time for success, time in results if success]) if successes > 0 else 0
success_rate = (successes / concurrent_requests) * 100
# Score based on success rate and speed under load
if success_rate > 90 and avg_time < 2:
return 100
elif success_rate > 70 and avg_time < 5:
return 75
elif success_rate > 50:
return 50
else:
return 25
def _calculate_overall_score(self, results):
"""Calculate weighted overall score"""
weights = {
'success_rate': 0.3,
'average_speed': 0.2,
'anonymity_score': 0.2,
'concurrent_performance': 0.15,
'geo_accuracy': 0.15
}
# Normalize speed score (lower is better)
speed_score = max(0, 100 - (results['average_speed'] * 20)) if results['average_speed'] > 0 else 0
weighted_score = (
results['success_rate'] * weights['success_rate'] +
speed_score * weights['average_speed'] +
results['anonymity_score'] * weights['anonymity_score'] +
results['concurrent_performance'] * weights['concurrent_performance'] +
results['geo_accuracy'] * weights['geo_accuracy']
)
return round(weighted_score, 2)
# Usage example
evaluator = ProxyProviderEvaluator()
# Configure providers to test
providers_to_test = [
{
'name': 'Datacenter Provider A',
'proxies': {'http': 'http://user:pass@dc-proxy.com:8080'},
'headers': {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'},
'expected_country': 'US'
},
{
'name': 'Residential Provider B',
'proxies': {'http': 'http://user:pass@res-proxy.com:8080'},
'headers': {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36'},
'expected_country': 'US'
}
]
# Evaluate each provider
for provider in providers_to_test:
results = evaluator.evaluate_provider(provider)
print(f"\n=== {provider['name']} ===")
print(f"Overall Score: {results['overall_score']}/100")
print(f"Success Rate: {results['success_rate']:.1f}%")
print(f"Average Speed: {results['average_speed']:.2f}s")
print(f"Anonymity Score: {results['anonymity_score']}/100")
print(f"Concurrent Performance: {results['concurrent_performance']}/100")
print(f"Geographic Accuracy: {results['geo_accuracy']}/100")Best Practices for Using Proxies in Web Scraping

Utilizing proxies effectively is crucial for ensuring a smooth and successful web scraping experience. In this section, we will discuss comprehensive best practices for using proxies in web scraping, including proxy rotation, managing proxy pools, error handling, and advanced optimization techniques.
Proxy Rotation Strategies
Proxy rotation is a critical technique in web scraping that involves systematically changing IP addresses to avoid detection, bans, and rate limiting. Effective rotation strategies can dramatically improve your scraping success rates and data quality.
Rotation Strategies:
1. Time-Based Rotation
- Rotate proxies after specific time intervals (e.g., every 60 seconds)
- Suitable for continuous scraping operations
- Helps distribute load evenly across proxy pool
2. Request-Based Rotation
- Change proxy after a set number of requests (e.g., every 50 requests)
- Useful for controlling proxy usage and costs
- Prevents overuse of individual IP addresses
3. Response-Based Rotation
- Rotate on specific HTTP status codes (403, 429, 503)
- Immediate response to blocking attempts
- Maintains high success rates during scraping
4. Intelligent Rotation
- AI-driven rotation based on success patterns
- Adapts to website behavior and anti-bot measures
- Maximizes efficiency and success rates
# Advanced intelligent proxy rotation system
import random
import time
from collections import defaultdict, deque
from datetime import datetime, timedelta
import threading
import requests
class IntelligentProxyRotator:
def __init__(self, proxy_list, learning_enabled=True):
self.proxy_list = proxy_list
self.learning_enabled = learning_enabled
# Statistics tracking
self.proxy_stats = defaultdict(lambda: {
'requests': 0,
'successes': 0,
'failures': 0,
'avg_response_time': 0,
'last_used': None,
'failure_streak': 0,
'success_streak': 0,
'hourly_usage': defaultdict(int),
'domain_performance': defaultdict(lambda: {'success': 0, 'total': 0})
})
# Rotation rules
self.rotation_rules = {
'max_requests_per_proxy': 100,
'max_failure_streak': 3,
'min_success_rate': 0.7,
'cooldown_period': 1800, # 30 minutes
'learning_window': 1000 # requests to consider for learning
}
# Banned proxies with timeout
self.banned_proxies = {}
self.lock = threading.Lock()
def get_best_proxy(self, domain=None, priority='balanced'):
"""Get the best proxy based on current statistics and domain"""
with self.lock:
# Clean up expired bans
self._cleanup_banned_proxies()
# Get available proxies
available_proxies = [
proxy for proxy in self.proxy_list
if proxy not in self.banned_proxies
]
if not available_proxies:
# If all proxies are banned, reset and use original list
self.banned_proxies.clear()
available_proxies = self.proxy_list
if not self.learning_enabled:
return random.choice(available_proxies)
# Score each proxy
proxy_scores = {}
for proxy in available_proxies:
score = self._calculate_proxy_score(proxy, domain, priority)
proxy_scores[proxy] = score
# Select best proxy
best_proxy = max(proxy_scores, key=proxy_scores.get)
return best_proxy
def _calculate_proxy_score(self, proxy, domain=None, priority='balanced'):
"""Calculate score for proxy selection"""
stats = self.proxy_stats[proxy]
# Base scores
success_rate = (stats['successes'] / max(stats['requests'], 1))
speed_score = max(0, 1 - (stats['avg_response_time'] / 10)) # Normalize to 0-1
# Domain-specific performance
domain_score = 1.0
if domain and domain in stats['domain_performance']:
domain_stats = stats['domain_performance'][domain]
domain_score = domain_stats['success'] / max(domain_stats['total'], 1)
# Recent performance (higher weight for recent activity)
recency_score = 1.0
if stats['last_used']:
hours_since_use = (datetime.now() - stats['last_used']).total_seconds() / 3600
recency_score = max(0.1, 1 - (hours_since_use / 24)) # Decay over 24 hours
# Failure streak penalty
streak_penalty = max(0, 1 - (stats['failure_streak'] * 0.2))
# Calculate weighted score based on priority
if priority == 'speed':
score = speed_score * 0.5 + success_rate * 0.3 + domain_score * 0.2
elif priority == 'reliability':
score = success_rate * 0.5 + domain_score * 0.3 + streak_penalty * 0.2
else: # balanced
score = (success_rate * 0.3 + speed_score * 0.25 +
domain_score * 0.25 + recency_score * 0.1 + streak_penalty * 0.1)
return score
def record_request_result(self, proxy, success, response_time, domain=None, status_code=None):
"""Record request result and update statistics"""
with self.lock:
stats = self.proxy_stats[proxy]
# Update basic stats
stats['requests'] += 1
stats['last_used'] = datetime.now()
if success:
stats['successes'] += 1
stats['failure_streak'] = 0
stats['success_streak'] += 1
# Update response time (exponential moving average)
if stats['avg_response_time'] == 0:
stats['avg_response_time'] = response_time
else:
stats['avg_response_time'] = (stats['avg_response_time'] * 0.8 +
response_time * 0.2)
else:
stats['failures'] += 1
stats['failure_streak'] += 1
stats['success_streak'] = 0
# Check if proxy should be banned
if (stats['failure_streak'] >= self.rotation_rules['max_failure_streak'] or
(stats['requests'] > 20 and
stats['successes'] / stats['requests'] < self.rotation_rules['min_success_rate'])):
self._ban_proxy(proxy, status_code)
# Update domain-specific stats
if domain:
domain_stats = stats['domain_performance'][domain]
domain_stats['total'] += 1
if success:
domain_stats['success'] += 1
def _ban_proxy(self, proxy, status_code=None):
"""Ban proxy temporarily"""
ban_duration = self.rotation_rules['cooldown_period']
# Extend ban for specific status codes
if status_code in [403, 429]:
ban_duration *= 2 # Double ban time for rate limiting
self.banned_proxies[proxy] = datetime.now() + timedelta(seconds=ban_duration)
print(f"Proxy {proxy} banned until {self.banned_proxies[proxy]}")
def _cleanup_banned_proxies(self):
"""Remove expired bans"""
current_time = datetime.now()
expired_bans = [
proxy for proxy, ban_time in self.banned_proxies.items()
if current_time > ban_time
]
for proxy in expired_bans:
del self.banned_proxies[proxy]
# Reset failure streak on unban
self.proxy_stats[proxy]['failure_streak'] = 0
def get_performance_report(self):
"""Generate performance report for all proxies"""
report = []
for proxy in self.proxy_list:
stats = self.proxy_stats[proxy]
if stats['requests'] > 0:
success_rate = (stats['successes'] / stats['requests']) * 100
report.append({
'proxy': proxy,
'requests': stats['requests'],
'success_rate': f"{success_rate:.1f}%",
'avg_response_time': f"{stats['avg_response_time']:.2f}s",
'current_streak': stats['success_streak'] if stats['success_streak'] > 0 else f"Fail: {stats['failure_streak']}",
'banned': proxy in self.banned_proxies
})
# Sort by success rate
report.sort(key=lambda x: float(x['success_rate'].replace('%', '')), reverse=True)
return report
# Usage with requests session
class OptimizedScrapingSession:
def __init__(self, proxy_rotator):
self.rotator = proxy_rotator
self.session = requests.Session()
def scrape_url(self, url, domain=None, priority='balanced', max_retries=3):
"""Scrape URL with intelligent proxy selection"""
for attempt in range(max_retries):
proxy = self.rotator.get_best_proxy(domain, priority)
proxies = {
'http': proxy,
'https': proxy
}
headers = {
'User-Agent': self._get_random_user_agent(),
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en-US,en;q=0.5',
'Accept-Encoding': 'gzip, deflate',
'Connection': 'keep-alive'
}
start_time = time.time()
try:
response = self.session.get(
url,
proxies=proxies,
headers=headers,
timeout=30
)
response_time = time.time() - start_time
# Record result
success = response.status_code == 200
self.rotator.record_request_result(
proxy,
success,
response_time,
domain,
response.status_code
)
if success:
return {
'success': True,
'content': response.text,
'proxy_used': proxy,
'response_time': response_time,
'attempt': attempt + 1
}
except requests.exceptions.RequestException as e:
response_time = time.time() - start_time
self.rotator.record_request_result(proxy, False, response_time, domain)
# Wait before retry
time.sleep(random.uniform(1, 3))
return {'success': False, 'error': 'Max retries exceeded'}
def _get_random_user_agent(self):
"""Get random user agent string"""
user_agents = [
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/121.0'
]
return random.choice(user_agents)
# Example usage
proxy_list = [
'http://user:pass@proxy1.com:8080',
'http://user:pass@proxy2.com:8080',
'http://user:pass@proxy3.com:8080'
]
# Initialize intelligent rotator
rotator = IntelligentProxyRotator(proxy_list, learning_enabled=True)
scraper = OptimizedScrapingSession(rotator)
# Scrape with domain-specific optimization
urls_to_scrape = [
('https://example-ecommerce.com/products', 'ecommerce.com'),
('https://news-site.com/articles', 'news-site.com')
]
for url, domain in urls_to_scrape:
result = scraper.scrape_url(url, domain=domain, priority='reliability')
if result['success']:
print(f"Successfully scraped {url} using {result['proxy_used']} in {result['response_time']:.2f}s")
else:
print(f"Failed to scrape {url}: {result.get('error')}")
# Generate performance report
report = rotator.get_performance_report()
print("\n=== Proxy Performance Report ===")
for entry in report:
print(f"Proxy: {entry['proxy']}")
print(f" Success Rate: {entry['success_rate']}")
print(f" Avg Response Time: {entry['avg_response_time']}")
print(f" Current Streak: {entry['current_streak']}")
print(f" Banned: {entry['banned']}\n")Managing Proxy Pools
Effective management of proxy pools is crucial for ensuring optimal performance and avoiding issues such as IP bans and slow response times. A well-managed proxy pool can significantly improve your scraping success rates and reduce operational costs.
Key Principles of Proxy Pool Management:
1. Pool Diversification
- Mix different proxy types (datacenter, residential, mobile)
- Use multiple providers to avoid single points of failure
- Distribute proxies across different geographic locations
- Maintain proxies from various IP ranges and ASNs
2. Health Monitoring
- Continuously monitor proxy performance and availability
- Implement automated health checks
- Track success rates, response times, and error patterns
- Remove or replace underperforming proxies
3. Load Balancing
- Distribute requests evenly across available proxies
- Implement intelligent routing based on proxy performance
- Consider proxy capabilities when assigning tasks
- Avoid overloading high-performing proxies
# Comprehensive proxy pool management system
import asyncio
import aiohttp
import time
from datetime import datetime, timedelta
from dataclasses import dataclass, field
from typing import List, Dict, Optional
from enum import Enum
import logging
import json
class ProxyStatus(Enum):
ACTIVE = "active"
DEGRADED = "degraded"
BANNED = "banned"
MAINTENANCE = "maintenance"
class ProxyType(Enum):
DATACENTER = "datacenter"
RESIDENTIAL = "residential"
MOBILE = "mobile"
ISP = "isp"
@dataclass
class ProxyInfo:
url: str
proxy_type: ProxyType
location: str
provider: str
cost_per_request: float = 0.0
max_concurrent: int = 10
status: ProxyStatus = ProxyStatus.ACTIVE
# Performance metrics
total_requests: int = 0
successful_requests: int = 0
avg_response_time: float = 0.0
last_used: Optional[datetime] = None
last_health_check: Optional[datetime] = None
# Health tracking
consecutive_failures: int = 0
health_score: float = 100.0
bandwidth_used: float = 0.0 # MB
def get_success_rate(self) -> float:
if self.total_requests == 0:
return 0.0
return (self.successful_requests / self.total_requests) * 100
def update_performance(self, success: bool, response_time: float):
self.total_requests += 1
self.last_used = datetime.now()
if success:
self.successful_requests += 1
self.consecutive_failures = 0
# Update average response time (exponential moving average)
if self.avg_response_time == 0:
self.avg_response_time = response_time
else:
self.avg_response_time = (self.avg_response_time * 0.8 + response_time * 0.2)
else:
self.consecutive_failures += 1
# Update health score
self._update_health_score()
def _update_health_score(self):
"""Calculate health score based on recent performance"""
success_rate = self.get_success_rate()
failure_penalty = min(self.consecutive_failures * 10, 50)
speed_bonus = max(0, 10 - self.avg_response_time)
self.health_score = max(0, success_rate - failure_penalty + speed_bonus)
class ProxyPoolManager:
def __init__(self, pool_config: Dict):
self.proxies: Dict[str, ProxyInfo] = {}
self.pool_config = pool_config
self.active_sessions: Dict[str, int] = {} # Track concurrent usage
# Configuration
self.health_check_interval = pool_config.get('health_check_interval', 300) # 5 minutes
self.max_consecutive_failures = pool_config.get('max_consecutive_failures', 5)
self.min_health_score = pool_config.get('min_health_score', 30)
# Background tasks
self.health_check_task = None
self.cleanup_task = None
async def add_proxy(self, proxy_info: ProxyInfo):
"""Add proxy to the pool"""
self.proxies[proxy_info.url] = proxy_info
self.active_sessions[proxy_info.url] = 0
# Perform initial health check
await self._health_check_proxy(proxy_info.url)
logging.info(f"Added proxy {proxy_info.url} to pool")
async def remove_proxy(self, proxy_url: str):
"""Remove proxy from the pool"""
if proxy_url in self.proxies:
del self.proxies[proxy_url]
del self.active_sessions[proxy_url]
logging.info(f"Removed proxy {proxy_url} from pool")
async def get_best_proxy(self, criteria: Dict = None) -> Optional[ProxyInfo]:
"""Get the best available proxy based on criteria"""
available_proxies = [
proxy for proxy in self.proxies.values()
if (proxy.status == ProxyStatus.ACTIVE and
proxy.health_score >= self.min_health_score and
self.active_sessions[proxy.url] < proxy.max_concurrent)
]
if not available_proxies:
return None
# Apply criteria filtering
if criteria:
available_proxies = self._filter_by_criteria(available_proxies, criteria)
if not available_proxies:
return None
# Score and select best proxy
best_proxy = max(available_proxies, key=self._calculate_proxy_score)
# Track usage
self.active_sessions[best_proxy.url] += 1
return best_proxy
def _filter_by_criteria(self, proxies: List[ProxyInfo], criteria: Dict) -> List[ProxyInfo]:
"""Filter proxies based on criteria"""
filtered = proxies
if 'proxy_type' in criteria:
filtered = [p for p in filtered if p.proxy_type == criteria['proxy_type']]
if 'location' in criteria:
filtered = [p for p in filtered if criteria['location'].lower() in p.location.lower()]
if 'max_cost_per_request' in criteria:
filtered = [p for p in filtered if p.cost_per_request <= criteria['max_cost_per_request']]
if 'min_success_rate' in criteria:
filtered = [p for p in filtered if p.get_success_rate() >= criteria['min_success_rate']]
return filtered
def _calculate_proxy_score(self, proxy: ProxyInfo) -> float:
"""Calculate score for proxy selection"""
# Base score from health
score = proxy.health_score
# Bonus for recent activity (proxies that have been tested recently)
if proxy.last_used:
hours_since_use = (datetime.now() - proxy.last_used).total_seconds() / 3600
recency_bonus = max(0, 10 - hours_since_use)
score += recency_bonus
# Penalty for high concurrent usage
usage_ratio = self.active_sessions[proxy.url] / proxy.max_concurrent
usage_penalty = usage_ratio * 20
score -= usage_penalty
# Speed bonus
if proxy.avg_response_time > 0:
speed_bonus = max(0, 5 - proxy.avg_response_time)
score += speed_bonus
return score
async def release_proxy(self, proxy_url: str, success: bool, response_time: float):
"""Release proxy after use and update metrics"""
if proxy_url in self.proxies:
proxy = self.proxies[proxy_url]
proxy.update_performance(success, response_time)
# Decrease active session count
if self.active_sessions[proxy_url] > 0:
self.active_sessions[proxy_url] -= 1
# Check if proxy should be banned
if (proxy.consecutive_failures >= self.max_consecutive_failures or
proxy.health_score < self.min_health_score):
proxy.status = ProxyStatus.BANNED
logging.warning(f"Proxy {proxy_url} banned due to poor performance")
async def _health_check_proxy(self, proxy_url: str) -> bool:
"""Perform health check on a single proxy"""
proxy = self.proxies[proxy_url]
test_urls = [
'https://httpbin.org/ip',
'https://httpbin.org/get'
]
success_count = 0
total_response_time = 0
async with aiohttp.ClientSession() as session:
for test_url in test_urls:
try:
start_time = time.time()
async with session.get(
test_url,
proxy=proxy_url,
timeout=aiohttp.ClientTimeout(total=30)
) as response:
response_time = time.time() - start_time
total_response_time += response_time
if response.status == 200:
success_count += 1
except Exception as e:
logging.debug(f"Health check failed for {proxy_url}: {e}")
# Update proxy status based on health check
success_rate = (success_count / len(test_urls)) * 100
avg_response_time = total_response_time / len(test_urls)
proxy.last_health_check = datetime.now()
if success_rate >= 50:
if proxy.status == ProxyStatus.BANNED:
proxy.status = ProxyStatus.ACTIVE
proxy.consecutive_failures = 0
logging.info(f"Proxy {proxy_url} restored to active status")
proxy.avg_response_time = avg_response_time
return True
else:
if proxy.status == ProxyStatus.ACTIVE:
proxy.status = ProxyStatus.DEGRADED
logging.warning(f"Proxy {proxy_url} marked as degraded")
return False
async def start_background_tasks(self):
"""Start background maintenance tasks"""
self.health_check_task = asyncio.create_task(self._periodic_health_check())
self.cleanup_task = asyncio.create_task(self._periodic_cleanup())
logging.info("Started proxy pool background tasks")
async def stop_background_tasks(self):
"""Stop background tasks"""
if self.health_check_task:
self.health_check_task.cancel()
if self.cleanup_task:
self.cleanup_task.cancel()
async def _periodic_health_check(self):
"""Periodically check health of all proxies"""
while True:
try:
logging.info("Starting periodic health check")
# Check proxies in batches to avoid overwhelming
proxy_urls = list(self.proxies.keys())
batch_size = 10
for i in range(0, len(proxy_urls), batch_size):
batch = proxy_urls[i:i + batch_size]
# Run health checks concurrently for batch
tasks = [self._health_check_proxy(url) for url in batch]
await asyncio.gather(*tasks, return_exceptions=True)
# Small delay between batches
await asyncio.sleep(5)
logging.info("Completed periodic health check")
except Exception as e:
logging.error(f"Error in periodic health check: {e}")
await asyncio.sleep(self.health_check_interval)
async def _periodic_cleanup(self):
"""Periodically clean up and optimize proxy pool"""
while True:
try:
# Reset banned proxies after cooldown period
cooldown_period = timedelta(hours=1)
current_time = datetime.now()
for proxy in self.proxies.values():
if (proxy.status == ProxyStatus.BANNED and
proxy.last_health_check and
current_time - proxy.last_health_check > cooldown_period):
proxy.status = ProxyStatus.ACTIVE
proxy.consecutive_failures = 0
proxy.health_score = 50 # Reset to neutral score
logging.info(f"Reset banned proxy {proxy.url} after cooldown")
except Exception as e:
logging.error(f"Error in periodic cleanup: {e}")
await asyncio.sleep(3600) # Run every hour
def get_pool_statistics(self) -> Dict:
"""Get comprehensive pool statistics"""
stats = {
'total_proxies': len(self.proxies),
'active_proxies': len([p for p in self.proxies.values() if p.status == ProxyStatus.ACTIVE]),
'banned_proxies': len([p for p in self.proxies.values() if p.status == ProxyStatus.BANNED]),
'degraded_proxies': len([p for p in self.proxies.values() if p.status == ProxyStatus.DEGRADED]),
'total_requests': sum(p.total_requests for p in self.proxies.values()),
'successful_requests': sum(p.successful_requests for p in self.proxies.values()),
'average_success_rate': 0,
'average_response_time': 0,
'proxy_types': {},
'locations': {},
'providers': {}
}
if stats['total_requests'] > 0:
stats['average_success_rate'] = (stats['successful_requests'] / stats['total_requests']) * 100
active_proxies = [p for p in self.proxies.values() if p.avg_response_time > 0]
if active_proxies:
stats['average_response_time'] = sum(p.avg_response_time for p in active_proxies) / len(active_proxies)
# Group by type, location, provider
for proxy in self.proxies.values():
# Proxy types
proxy_type = proxy.proxy_type.value
if proxy_type not in stats['proxy_types']:
stats['proxy_types'][proxy_type] = {'count': 0, 'active': 0}
stats['proxy_types'][proxy_type]['count'] += 1
if proxy.status == ProxyStatus.ACTIVE:
stats['proxy_types'][proxy_type]['active'] += 1
# Locations
location = proxy.location
if location not in stats['locations']:
stats['locations'][location] = {'count': 0, 'active': 0}
stats['locations'][location]['count'] += 1
if proxy.status == ProxyStatus.ACTIVE:
stats['locations'][location]['active'] += 1
# Providers
provider = proxy.provider
if provider not in stats['providers']:
stats['providers'][provider] = {'count': 0, 'active': 0, 'success_rate': 0}
stats['providers'][provider]['count'] += 1
if proxy.status == ProxyStatus.ACTIVE:
stats['providers'][provider]['active'] += 1
return stats
# Usage example
async def main():
# Configure proxy pool
pool_config = {
'health_check_interval': 300, # 5 minutes
'max_consecutive_failures': 3,
'min_health_score': 40
}
# Initialize pool manager
pool_manager = ProxyPoolManager(pool_config)
# Add proxies to the pool
proxies_to_add = [
ProxyInfo(
url='http://user:pass@dc-proxy1.com:8080',
proxy_type=ProxyType.DATACENTER,
location='US-East',
provider='DatacenterProvider',
cost_per_request=0.001,
max_concurrent=50
),
ProxyInfo(
url='http://user:pass@res-proxy1.com:8080',
proxy_type=ProxyType.RESIDENTIAL,
location='US-West',
provider='ResidentialProvider',
cost_per_request=0.01,
max_concurrent=10
)
]
for proxy_info in proxies_to_add:
await pool_manager.add_proxy(proxy_info)
# Start background tasks
await pool_manager.start_background_tasks()
# Example usage
criteria = {
'proxy_type': ProxyType.DATACENTER,
'min_success_rate': 80,
'max_cost_per_request': 0.005
}
# Get best proxy for scraping
proxy = await pool_manager.get_best_proxy(criteria)
if proxy:
print(f"Selected proxy: {proxy.url}")
# Simulate scraping request
start_time = time.time()
success = True # Simulate successful request
response_time = time.time() - start_time
# Release proxy and update metrics
await pool_manager.release_proxy(proxy.url, success, response_time)
# Get pool statistics
stats = pool_manager.get_pool_statistics()
print(f"Pool stats: {json.dumps(stats, indent=2)}")
# Stop background tasks
await pool_manager.stop_background_tasks()
# Run the example
if __name__ == "__main__":
asyncio.run(main())Error Handling and Troubleshooting
Proper error handling and troubleshooting techniques can help identify and resolve issues related to proxies, ensuring a smooth web scraping experience. A robust error handling system can automatically recover from failures and maintain high scraping success rates.
Common Proxy-Related Errors:
- Connection timeouts
- Authentication failures
- Rate limiting (HTTP 429)
- IP bans (HTTP 403)
- Proxy server errors (HTTP 5xx)
- DNS resolution failures
- SSL/TLS handshake errors
# Comprehensive error handling and recovery system
import requests
import time
import random
from enum import Enum
from dataclasses import dataclass
from typing import Dict, List, Optional, Callable
import logging
from datetime import datetime, timedelta
class ErrorType(Enum):
CONNECTION_ERROR = "connection_error"
TIMEOUT_ERROR = "timeout_error"
AUTH_ERROR = "auth_error"
RATE_LIMIT = "rate_limit"
IP_BAN = "ip_ban"
SERVER_ERROR = "server_error"
SSL_ERROR = "ssl_error"
DNS_ERROR = "dns_error"
UNKNOWN_ERROR = "unknown_error"
@dataclass
class RecoveryStrategy:
retry_count: int = 3
retry_delay: float = 1.0
exponential_backoff: bool = True
switch_proxy: bool = True
custom_handler: Optional[Callable] = None
class ProxyErrorHandler:
def __init__(self):
self.error_patterns = {
ErrorType.CONNECTION_ERROR: [
"Connection refused",
"Connection reset",
"No route to host"
],
ErrorType.TIMEOUT_ERROR: [
"timeout",
"timed out",
"Read timeout"
],
ErrorType.AUTH_ERROR: [
"407 Proxy Authentication Required",
"Authentication failed"
],
ErrorType.RATE_LIMIT: ["429", "Too Many Requests"],
ErrorType.IP_BAN: ["403", "Forbidden", "Access denied"],
ErrorType.SERVER_ERROR: ["500", "502", "503", "504"],
ErrorType.SSL_ERROR: ["SSL", "certificate", "handshake"],
ErrorType.DNS_ERROR: ["Name resolution", "DNS", "getaddrinfo"]
}
# Default recovery strategies
self.recovery_strategies = {
ErrorType.CONNECTION_ERROR: RecoveryStrategy(
retry_count=3,
retry_delay=2.0,
switch_proxy=True
),
ErrorType.TIMEOUT_ERROR: RecoveryStrategy(
retry_count=2,
retry_delay=5.0,
switch_proxy=True
),
ErrorType.AUTH_ERROR: RecoveryStrategy(
retry_count=1,
retry_delay=0.0,
switch_proxy=True
),
ErrorType.RATE_LIMIT: RecoveryStrategy(
retry_count=3,
retry_delay=10.0,
exponential_backoff=True,
switch_proxy=True
),
ErrorType.IP_BAN: RecoveryStrategy(
retry_count=1,
retry_delay=0.0,
switch_proxy=True
),
ErrorType.SERVER_ERROR: RecoveryStrategy(
retry_count=2,
retry_delay=3.0,
switch_proxy=False
),
ErrorType.SSL_ERROR: RecoveryStrategy(
retry_count=2,
retry_delay=1.0,
switch_proxy=True
),
ErrorType.DNS_ERROR: RecoveryStrategy(
retry_count=2,
retry_delay=1.0,
switch_proxy=True
)
}
# Error statistics
self.error_stats = {error_type: 0 for error_type in ErrorType}
def classify_error(self, error) -> ErrorType:
"""Classify error based on error message and type"""
error_str = str(error).lower()
# Check HTTP status codes first
if hasattr(error, 'response') and error.response:
status_code = error.response.status_code
if status_code == 407:
return ErrorType.AUTH_ERROR
elif status_code == 429:
return ErrorType.RATE_LIMIT
elif status_code == 403:
return ErrorType.IP_BAN
elif 500 <= status_code < 600:
return ErrorType.SERVER_ERROR
# Check error message patterns
for error_type, patterns in self.error_patterns.items():
for pattern in patterns:
if pattern.lower() in error_str:
return error_type
return ErrorType.UNKNOWN_ERROR
def get_recovery_strategy(self, error_type: ErrorType) -> RecoveryStrategy:
"""Get recovery strategy for error type"""
return self.recovery_strategies.get(error_type, RecoveryStrategy())
def record_error(self, error_type: ErrorType):
"""Record error for statistics"""
self.error_stats[error_type] += 1
def get_error_statistics(self) -> Dict:
"""Get error statistics"""
total_errors = sum(self.error_stats.values())
if total_errors == 0:
return {"total_errors": 0, "error_distribution": {}}
error_distribution = {
error_type.value: {
"count": count,
"percentage": (count / total_errors) * 100
}
for error_type, count in self.error_stats.items()
if count > 0
}
return {
"total_errors": total_errors,
"error_distribution": error_distribution
}
class ResilientProxyScraper:
def __init__(self, proxy_list: List[str]):
self.proxy_list = proxy_list
self.current_proxy_index = 0
self.error_handler = ProxyErrorHandler()
self.session = requests.Session()
# Circuit breaker for proxies
self.proxy_failures = {proxy: 0 for proxy in proxy_list}
self.proxy_ban_until = {}
def get_next_proxy(self) -> str:
"""Get next available proxy with circuit breaker logic"""
current_time = datetime.now()
# Remove expired bans
self.proxy_ban_until = {
proxy: ban_time for proxy, ban_time in self.proxy_ban_until.items()
if current_time < ban_time
}
# Find available proxy
available_proxies = [
proxy for proxy in self.proxy_list
if proxy not in self.proxy_ban_until
]
if not available_proxies:
# If all proxies are banned, reset bans and use original list
self.proxy_ban_until.clear()
available_proxies = self.proxy_list
logging.warning("All proxies were banned, resetting ban list")
# Get proxy with least failures
best_proxy = min(available_proxies, key=lambda p: self.proxy_failures[p])
return best_proxy
def ban_proxy_temporarily(self, proxy: str, duration_minutes: int = 30):
"""Temporarily ban a proxy"""
ban_until = datetime.now() + timedelta(minutes=duration_minutes)
self.proxy_ban_until[proxy] = ban_until
logging.warning(f"Proxy {proxy} banned until {ban_until}")
def make_resilient_request(self, url: str, **kwargs) -> Optional[requests.Response]:
"""Make request with comprehensive error handling and recovery"""
max_proxy_switches = len(self.proxy_list)
proxy_switches = 0
while proxy_switches < max_proxy_switches:
proxy = self.get_next_proxy()
proxies = {
'http': proxy,
'https': proxy
}
# Merge proxies with any provided proxies
if 'proxies' in kwargs:
kwargs['proxies'].update(proxies)
else:
kwargs['proxies'] = proxies
# Set default timeout if not provided
if 'timeout' not in kwargs:
kwargs['timeout'] = 30
# Set default headers if not provided
if 'headers' not in kwargs:
kwargs['headers'] = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
try:
response = self.session.get(url, **kwargs)
# Reset failure count on success
self.proxy_failures[proxy] = 0
# Check for rate limiting or bans in successful responses
if response.status_code == 429:
raise requests.exceptions.HTTPError(f"429 Too Many Requests", response=response)
elif response.status_code == 403:
raise requests.exceptions.HTTPError(f"403 Forbidden", response=response)
return response
except Exception as e:
error_type = self.error_handler.classify_error(e)
self.error_handler.record_error(error_type)
logging.error(f"Request failed with proxy {proxy}: {error_type.value} - {e}")
# Increment failure count
self.proxy_failures[proxy] += 1
# Get recovery strategy
strategy = self.error_handler.get_recovery_strategy(error_type)
# Handle specific error types
if error_type in [ErrorType.IP_BAN, ErrorType.RATE_LIMIT]:
# Ban proxy temporarily for these errors
ban_duration = 30 if error_type == ErrorType.IP_BAN else 60
self.ban_proxy_temporarily(proxy, ban_duration)
proxy_switches += 1
continue
elif error_type == ErrorType.AUTH_ERROR:
# Authentication errors are usually permanent for a proxy
self.ban_proxy_temporarily(proxy, 120) # 2 hours
proxy_switches += 1
continue
# Implement retry logic with exponential backoff
for attempt in range(strategy.retry_count):
delay = strategy.retry_delay
if strategy.exponential_backoff:
delay *= (2 ** attempt)
# Add jitter to prevent thundering herd
delay += random.uniform(0, delay * 0.1)
logging.info(f"Retrying in {delay:.2f} seconds (attempt {attempt + 1}/{strategy.retry_count})")
time.sleep(delay)
try:
response = self.session.get(url, **kwargs)
# Success after retry
self.proxy_failures[proxy] = max(0, self.proxy_failures[proxy] - 1)
return response
except Exception as retry_error:
retry_error_type = self.error_handler.classify_error(retry_error)
logging.error(f"Retry {attempt + 1} failed: {retry_error_type.value}")
# If we get a different error type, break retry loop
if retry_error_type != error_type:
break
# If all retries failed and strategy allows proxy switching
if strategy.switch_proxy:
proxy_switches += 1
# Ban proxy if too many failures
if self.proxy_failures[proxy] >= 5:
self.ban_proxy_temporarily(proxy, 60)
continue
else:
# Strategy doesn't allow proxy switching, give up
break
logging.error(f"All proxies exhausted for URL: {url}")
return None
def scrape_with_resilience(self, urls: List[str], **kwargs) -> List[Dict]:
"""Scrape multiple URLs with resilient error handling"""
results = []
for i, url in enumerate(urls):
logging.info(f"Scraping URL {i+1}/{len(urls)}: {url}")
start_time = time.time()
response = self.make_resilient_request(url, **kwargs)
response_time = time.time() - start_time
if response:
results.append({
'url': url,
'success': True,
'status_code': response.status_code,
'content': response.text,
'response_time': response_time,
'proxy_used': response.request.proxies.get('http', 'Unknown')
})
logging.info(f"Successfully scraped {url} in {response_time:.2f}s")
else:
results.append({
'url': url,
'success': False,
'error': 'All recovery attempts failed',
'response_time': response_time
})
logging.error(f"Failed to scrape {url}")
# Respectful delay between requests
time.sleep(random.uniform(1, 3))
return results
def get_scraping_report(self) -> Dict:
"""Generate comprehensive scraping report"""
error_stats = self.error_handler.get_error_statistics()
proxy_stats = []
for proxy in self.proxy_list:
is_banned = proxy in self.proxy_ban_until
ban_until = self.proxy_ban_until.get(proxy, None)
proxy_stats.append({
'proxy': proxy,
'failures': self.proxy_failures[proxy],
'is_banned': is_banned,
'ban_until': ban_until.isoformat() if ban_until else None
})
return {
'error_statistics': error_stats,
'proxy_statistics': proxy_stats,
'total_proxies': len(self.proxy_list),
'banned_proxies': len(self.proxy_ban_until),
'available_proxies': len(self.proxy_list) - len(self.proxy_ban_until)
}
# Usage example
def main():
# Configure logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# Initialize scraper with proxy list
proxy_list = [
'http://user:pass@proxy1.com:8080',
'http://user:pass@proxy2.com:8080',
'http://user:pass@proxy3.com:8080'
]
scraper = ResilientProxyScraper(proxy_list)
# URLs to scrape
urls_to_scrape = [
'https://httpbin.org/ip',
'https://httpbin.org/user-agent',
'https://example.com',
'https://httpbin.org/status/403', # This will trigger IP ban handling
'https://httpbin.org/delay/10' # This might trigger timeout
]
# Scrape with resilience
results = scraper.scrape_with_resilience(urls_to_scrape)
# Print results
successful_scrapes = sum(1 for r in results if r['success'])
print(f"\nScraping completed: {successful_scrapes}/{len(urls_to_scrape)} successful")
for result in results:
if result['success']:
print(f"✓ {result['url']} - {result['status_code']} - {result['response_time']:.2f}s")
else:
print(f"✗ {result['url']} - {result['error']}")
# Generate and print report
report = scraper.get_scraping_report()
print("\n=== Scraping Report ===")
print(f"Error Statistics: {report['error_statistics']}")
print(f"Available Proxies: {report['available_proxies']}/{report['total_proxies']}")
if report['proxy_statistics']:
print("\nProxy Status:")
for proxy_stat in report['proxy_statistics']:
status = "BANNED" if proxy_stat['is_banned'] else "ACTIVE"
print(f" {proxy_stat['proxy']}: {status} (failures: {proxy_stat['failures']})")
if __name__ == "__main__":
main()Summary
In conclusion, proxies play a vital role in web scraping by enabling users to bypass restrictions, maintain anonymity, and access geo-restricted content. By understanding the different types of proxies, their advantages and drawbacks, and best practices for using them, you can choose the right proxy provider and optimize your web scraping projects.
Key Takeaways:
Choose the Right Proxy Type: Datacenter proxies for speed and cost-effectiveness, residential proxies for anonymity and success rates, mobile proxies for highest trust levels, and specialized proxies for advanced features.
Implement Smart Rotation: Use intelligent rotation strategies that consider proxy performance, domain-specific optimization, and failure patterns.
Manage Your Pool Effectively: Monitor proxy health, distribute load evenly, and maintain a diverse mix of proxy types and locations.
Handle Errors Gracefully: Implement comprehensive error handling with automatic recovery, circuit breakers, and intelligent retry mechanisms.
Monitor and Optimize: Continuously track proxy performance, analyze error patterns, and optimize your strategy based on real-world results.
Remember to consider factors such as IP pool size, geolocation options, response time, and anonymity when selecting a provider, and always implement proxy rotation, manage proxy pools, and handle errors effectively. With these strategies in place, you're well-equipped to achieve web scraping success while maintaining ethical and respectful scraping practices.
Frequently Asked Questions
What proxy to use for web scraping?
The best proxy type depends on your specific needs. For general web scraping, datacenter proxies offer the best balance of speed and cost. For social media and e-commerce sites with advanced bot detection, residential proxies provide better success rates. For the highest success rates and mobile-specific content, mobile proxies are ideal despite their higher cost.
What proxies are best for Google scraping?
For Google scraping, residential proxies are the best choice due to their high legitimacy and low detection rates. Google has sophisticated anti-bot measures, making residential proxies essential for consistent access. Consider using rotating residential proxies with geo-targeting to avoid rate limiting and access location-specific results.
What are the three main types of proxy protocols?
The three main proxy protocols are:
- HTTP Proxies: Most common, work with web traffic and support HTTP/HTTPS
- SOCKS Proxies: More versatile, can handle any type of traffic (HTTP, FTP, SMTP, etc.)
- HTTPS/SSL Proxies: Encrypted proxy connections for secure data transmission
Each protocol provides different levels of security, speed, and compatibility for various web scraping needs.
What is the main purpose of proxies in web scraping?
Proxies serve multiple critical purposes in web scraping:
- Anonymity: Hide your real IP address and location from target websites
- Bypass Restrictions: Access geo-blocked content and circumvent IP-based blocking
- Scale Operations: Enable high-volume scraping through IP rotation and load distribution
- Avoid Rate Limiting: Distribute requests across multiple IPs to prevent throttling
- Maintain Access: Ensure continuous scraping operations without interruption from bans
How much do proxies cost for web scraping?
Proxy costs vary significantly by type:
- Datacenter Proxies: $1-5 per IP per month, or $50-200 for shared pools
- Residential Proxies: $5-15 per GB of traffic, or $200-800 monthly for dedicated access
- Mobile Proxies: $20-100+ per IP per month, typically $500-2000 for quality providers
- Specialized/Enterprise: $1000-5000+ monthly for advanced features and support
Choose based on your budget, required anonymity level, and scraping volume.