Ever wondered about the magic behind web scraping – the art of extracting valuable data from websites? More specifically, have you considered the power of Go, also known as Golang, in this field? As an open-source programming language developed by Google, Go is no stranger to robust performance and efficiency. Its speed and simplicity, coupled with a rich library collection, make it a go-to language for many programmers. Now, imagine combining these power-packed features with the vast world of web scraping using “Go libraries for web scraping”. Intrigued? Let’s unravel this exciting synergy, shall we?
Key Takeaways
- Go is an easily accessible and powerful language for web scraping, providing faster collection speed, concurrent request processing and extensive library support.
- Leverage Go’s concurrency features such as goroutines to achieve parallel web scraping tasks.
- Use essential libraries like Colly, GoQuery & Pholcus for data extraction capabilities and advanced features such as dynamic page rendering & proxy rotation.
Unlocking the Power of Go for Web Scraping

The field of web scraping is varied, offering numerous languages and tools for our use. Yet, for many, Go stands out from the crowd. Its simplicity allows for a smooth learning curve, making it a favorite among beginners and seasoned programmers alike. But it’s not just about ease of use. Go’s unique built-in support for concurrency and its extensive library collection, including tools like Colly, GoQuery, and Pholcus, provide a powerful toolkit for any web scraping mission.
From initiating HTTP requests to dissecting HTML documents, Go libraries are reliable partners in the process of data extraction.
Why Choose Go for Your Web Scraping Needs?
Selecting the right programming language is a significant factor in web scraping. After all, it’s the foundation upon which our data extraction efforts rest. So, why Go? The answer lies in its unique blend of simplicity and power. Go’s simplicity translates to speed and efficiency, enabling faster and more streamlined data collection from websites compared to traditional scripting languages.
Moreover, Go’s ability to process concurrently lets multiple scraping requests run at the same time, making it a perfect choice for extensive projects. And with the support of key Go libraries, tasks such as HTML parsing, proxy rotation, and CAPTCHA solving become a breeze.
The Concurrency Edge: Multiprocessing in Go
One of Go’s key strengths lies in its built-in support for concurrency, embodied by goroutines - lightweight threads that enable parallel execution. This feature is particularly useful in web scraping, where efficiency in data extraction is paramount. Imagine trying to extract data from multiple pages of a website. With Go’s support for concurrent execution, you can scrape multiple pages simultaneously, significantly reducing the overall time spent on the task.
This parallel web scraping is achieved by leveraging the OnHTML() function and other methods in Colly to implement the scraping logic and extract HTML attributes from the target page.
Essential Go Libraries for Effective Data Extraction

Go’s strength is not limited to its core features, but also extends to its extensive array of libraries. These libraries act as your companions in the web scraping journey, providing much-needed tools and capabilities. Among the many available, three stand out for their popularity and effectiveness:
- Colly: This library offers advanced features like dynamic page rendering and regular expression extraction.
- GoQuery: This library is great for parsing HTML documents and extracting data.
- Pholcus: This library is known for its distributed scraping capabilities.
Beyond the basics of making HTTP requests and parsing an HTML document, web scraping libraries offer advanced features like dynamic page rendering, regular expression extraction, and distributed scraping.
And it’s not just about data extraction. They also aid in the following steps of data processing and cleaning, making sure you have clean, precise, and dependable data for your analysis.
Colly: The Agile Web Scraper
First on our list is Colly, a high-speed and adaptable web scraping framework for Go. Colly provides a straightforward API and a suite of sophisticated features that make it a top choice among Go developers. With Colly, you can:
- Execute asynchronous web page requests, enhancing performance and minimizing scraping time
- Effectively handle JavaScript on the page
- Offer user-friendly methods for website interactions
From executing a callback function when it finds HTML elements that match a specific selector to extracting the attribute value and text of an HTML child through a CSS selector, Colly is an agile web scraper that gets the job done efficiently.
GoQuery: jQuery-like HTML Parsing
Next up is GoQuery, a Go package that provides a syntax and function set akin to jQuery for parsing HTML documents. GoQuery simplifies the extraction of specific data from web pages by offering the power and flexibility of CSS selectors.
Whether you’re scraping a simple website or dealing with complex web documents, GoQuery’s practical approach to HTML parsing makes it an invaluable tool in your Go web scraping toolkit.
Pholcus: High-Concurrency Scraping Framework
Last but not least, meet Pholcus, a high-concurrency web scraping framework for Go. Pholcus provides a comprehensive set of tools for data extraction, from regular expressions to XPath and CSS selectors. While it may pose a learning curve for beginners due to its elaborate features and less comprehensive documentation, Pholcus shines in its ability to handle large-scale, high-concurrency scraping tasks.
It’s particularly useful when dealing with websites that have IP restrictions or when there’s a need to guarantee anonymity during scraping.
Setting Up Your Go Scraping Environment
Armed with the power of Go and its libraries, it’s time to prepare for our web scraping operations. The first step in this process is to install Go and establish a new Go project. Once that’s done, we need to configure our development environment.
For Go web scraping, Visual Studio Code (VS Code) is a recommended choice. It’s versatile, powerful, and comes with a slew of Go extensions that make the development process smoother and more efficient.
Installation Essentials: Getting Go Ready
The journey starts with installing Go – an essential step to unlock its powerful features. The installation process varies depending on the operating system but remains straightforward. Once Go is installed, you can verify the installation by running the go version command in your terminal. If the command returns the current Go version without any issues, congratulations, you’ve successfully installed Go, and you’re ready to dive into the world of Go web scraping.
Tooling Up: Visual Studio Code and Go Extensions
With Go now installed, we move on to setting up our development environment. Visual Studio Code, with its rich feature set and extensive Go extensions, is an excellent choice for Go web scraping. From IntelliSense and code navigation to testing and debugging, VS Code enhances productivity and makes the development process a breeze.
With Go extension for Visual Studio Code and GoColly, you can enjoy a seamless web scraping development experience, all within the comfort of VS Code.
Crafting Your First Scraper with Go

With the initial setup complete, we can now focus on creating our first web scraper with Go. From selecting targets to structuring your Go code, this process involves a series of steps that will help you harvest valuable data from the vast fields of the internet.
So, are you ready to put your Go skills into practice and extract some data?
Selecting Targets: Inspecting HTML Elements
The first step in web scraping is to identify the ‘what’ - the data you wish to extract. This involves analyzing the HTML code of the web page to identify the elements that contain the data of interest. Whether it’s the text within a div tag or the link in an a tag, careful inspection of HTML elements is crucial to target the right data for extraction.
Writing the Scraper: Structuring Your Go Code
After identifying the target website, the next step is to write the scraper. This involves structuring your Go code in a way that navigates the web page, extracts the required data, and stores it for further analysis. From initiating the scraping process with a visit to the target URL to extracting text from HTML elements, this step involves writing the commands that tell the scraper what to do and how to do it.
Remember, a well-structured Go scraper not only extracts data effectively but also handles potential errors and ensures smooth execution of the scraping process.
Advanced Data Handling Techniques

As you progress in your Go web scraping endeavors, you’ll come across more intricate scraping scenarios that require sophisticated data handling techniques. Whether it’s scraping dynamic content that’s loaded by JavaScript, navigating through multiple pages of a website, or storing the extracted data for analysis, Go offers a range of features and libraries to tackle these challenges.
Let’s take a closer look at these techniques.
Scrape Dynamic Content: Headless Browser Capabilities
Dynamic content refers to website content that is loaded or changed by JavaScript after the initial page load. Traditional web scrapers that only download the HTML source code of a page may not be able to access this dynamic content. However, with Go’s headless browser libraries like chromedp, you can simulate a real browser that loads the full page, including any dynamic content.
This allows you to scrape data that would otherwise be hidden from a traditional scraper.
Navigating Pages: Handling Pagination in Scrapers
Pagination is a common feature on many websites, where content is split across multiple pages. For a web scraper, this means it needs to navigate these multiple pages to extract all the required data. Go offers features like loops and conditional statements that can be used to navigate through paginated pages.
By finding the ‘next’ button and creating a loop that visits each successive page, you can ensure your scraper captures all the data across all the pages.
From HTML to CSV: Storing Extracted Data
After extracting the required data, the next step is to store it for further analysis or reporting. Go provides easy-to-use functions for writing data to files, including CSV files. By defining a data structure that matches the extracted data and using Go’s built-in csv package, you can write the scraped data to a CSV file.
This allows you to easily share the data, open it in spreadsheet software like Excel, or import it into a database for further processing.
Optimizing Your Go Scraper Performance
As with any other software application, performance plays a vital role in web scraping. A high-performing web scraper not only completes its task faster but also consumes fewer resources, which can be crucial if you’re scraping a large website or running many scrapers at once. Go offers several features and best practices to optimize your web scraper’s performance, from efficient memory management to parallel scraping with goroutines.
Managing Memory: Efficient Use of Pointers
One of the ways to optimize your Go web scraper’s performance is through efficient memory management. Go provides automatic memory management, which means you don’t have to manually allocate and deallocate memory. However, understanding how Go uses memory, and how you can influence it, can help you write more efficient code.
For example, using pointers can sometimes help reduce memory usage by avoiding unnecessary copying of data. On the other hand, excessive use of pointers can lead to higher memory usage and slower performance, so it’s important to use them judiciously.
Scaling Up: Parallel Scraping with Goroutines
Another way to enhance the performance of your Go web scraper is through parallel scraping. This involves running multiple scraping tasks simultaneously, which can significantly reduce the overall time taken, especially when scraping large websites. Go’s support for concurrency, through features like goroutines and channels, makes it well-suited for parallel scraping.
By creating a separate goroutine for each page to be scraped and using channels to communicate the results, you can turn your single-threaded scraper into a high-performing, parallel scraping machine.
Dealing with Common Web Scraping Challenges
Like every technology, web scraping with Go has its own set of challenges. Websites may implement anti-scraping measures that could block your scraper, or you may need to deal with complex page structures or dynamic content. Fortunately, Go offers various features and libraries that help you overcome these challenges.
Let’s explore some of the common challenges in Go and how to deal with them, starting with the package main import process.
Mimicking Browsers: Setting a Valid User-Agent Header
One common anti-scraping measure employed by websites is to block requests that do not appear to come from a real web browser. One way websites determine this is by looking at the User-Agent header of the HTTP request. By setting a valid User-Agent header that mimics a real web browser, you can make your scraper’s requests appear more legitimate and reduce the chances of being blocked.
Go libraries like Colly allow you to easily set a global User-Agent header for all your scraper’s requests.
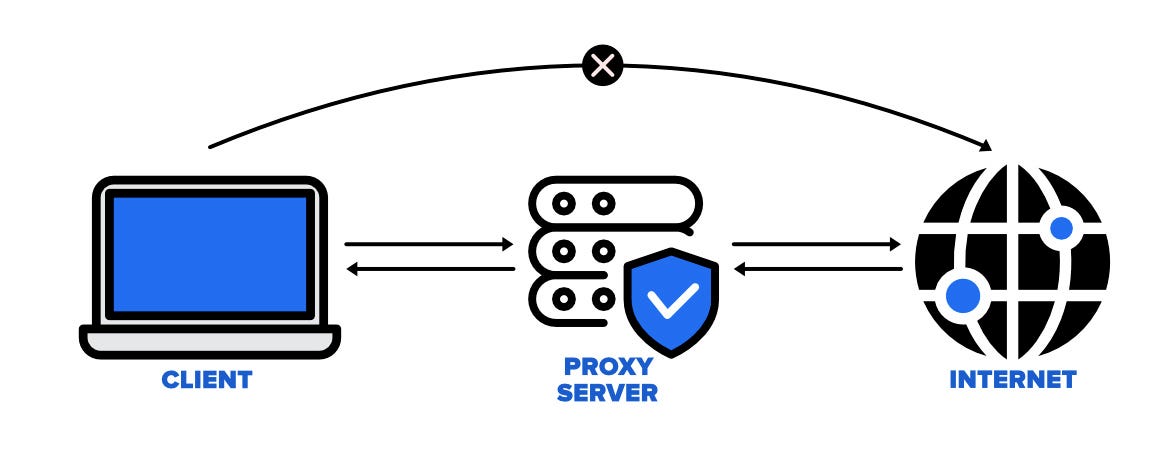
Circumventing Blocks: Proxy Rotation and CAPTCHA Solving
Another common challenge in web scraping is dealing with IP blocks and CAPTCHAs. Websites may block IP addresses that make too many requests in a short period or present a CAPTCHA test to verify that the user is a human. Proxy rotation, which involves making requests through different IP addresses, and CAPTCHA-solving services can help overcome these challenges.
Go libraries like Colly and Anti-Captcha provide features for proxy rotation and CAPTCHA solving, allowing your scraper to continue its work uninterrupted.
Leveraging Web Scraping APIs with Go
Although Go and its libraries provide a potent toolset for web scraping, web scraping APIs offer another layer of simplicity to your web scraping tasks. These APIs provide a structured and reliable way to extract data from websites, taking care of many of the common challenges in web scraping.
By integrating a web scraping API into your Go scraper, you can simplify your code, improve reliability, and focus on what really matters: the data.
The Role of APIs in Simplified Scraping
Web scraping APIs provide an interface to a web scraping service, allowing you to request data from a website without having to deal with the complexities of web scraping. You simply send a request to the API with the URL of the website you want to scrape, and the API returns the data in a structured format like JSON or XML. This not only simplifies the web scraping process but also provides a more reliable way to access data, as the API takes care of handling dynamic content, dealing with CAPTCHAs, and other common challenges.
Integrating APIs into Your Go Scraping Logic
Incorporating a web scraping API into your Go scraper can be as simple as making an HTTP request. Most web scraping APIs provide a RESTful interface, which you can access using Go’s net/http package. Once you receive the response from the API, you can parse it using Go’s json or xml package and use the data as required.
Many APIs also provide client libraries in Go, making it even easier to integrate them into your scraper. With an API handling the hard parts of web scraping, you can focus on what to do with the data.
Summary
Web scraping can be a complex task, but with Go and its powerful libraries, you’ve got a toolkit that can tackle any challenge. From extracting data from HTML elements to handling dynamic content and pagination, Go offers a range of features and libraries that make web scraping a breeze. And with the addition of web scraping APIs, you can even offload some of the scraping tasks to a dedicated service, making your scraper simpler and more reliable. So why not give Go a go for your next web scraping project? You might be surprised at what you can achieve.
Frequently Asked Questions
Is Golang good for web scraping?
Overall, Go is an excellent choice for web scraping tasks due to its high performance capabilities and ability to efficiently handle concurrency.
Which library is best for web scraping?
Scrapy and Beautiful Soup have consistently been rated the top libraries for web scraping in 2023, so they are your best bet for reliable results. Make sure to check for any artifacts when extracting data.
How to build a web scraper in Golang?
To build a web scraper in Golang, set up a Go project, install Colly, connect to the target website, inspect the HTML page, select elements with Colly, scrape data from the webpage, export the extracted data, and finally put it all together.
What is the R library for web scraping?
rvest is an R library specifically designed for web scraping, providing an advanced API to easily download, parse, and select HTML elements to extract data from.
How can I handle common web scraping challenges like IP blocks and CAPTCHAs in Go?
To handle web scraping challenges such as IP blocks and CAPTCHAs, use a valid User-Agent header, proxy rotation, and CAPTCHA-solving services.