In the era of data, the potency of information is undeniable. However, the extraction of this golden nugget from the vast web is not without its challenges. Enter Java, a mighty tool that has come to the rescue of many who are lost in the labyrinth of web scraping. But how, you ask? That’s the intriguing journey we’re about to embark on, exploring the world of Java libraries for web scraping.
Key Takeaways
- Explore the range of Java web scraping libraries, such as Jsoup, HtmlUnit, WebMagic and Selenium.
- Set up your environment with an IDE like IntelliJ IDEA or Eclipse to import necessary libraries.
- Leverage advanced techniques for efficient data extraction by utilizing multithreading and headless browsers while adhering to best practices for successful web scraping in Java.
Overview of Java Web Scraping Libraries

Java’s strength in web scraping stems from its comprehensive set of libraries. These libraries handle different aspects of web scraping, enhancing efficiency and effectiveness. This post will examine four notable libraries:
- Jsoup
- HtmlUnit
- WebMagic
- Selenium
Each library is recognized for its unique capabilities and applications.
Jsoup
Have you ever tried to read a book with no punctuation or spaces? It’s a challenge, isn’t it? That’s what parsing HTML documents can feel like. But don’t fret, Jsoup is here to save the day. This popular Java library is like a grammar expert for your HTML documents. It employs a user-friendly API that allows for easy data extraction and manipulation, making your web scraping adventure a breeze.
The magic of Jsoup lies in its ability to turn a chaotic jumble of HTML into a neat, structured form that you can navigate with ease. By employing the Jsoup.parse method, it loads HTML content into a format that lets you find, access, and manipulate DOM elements. It’s like having a personal guide to lead you through the HTML jungle, pointing out the data you need.
HtmlUnit
Imagine walking through a city with no map or GPS. That’s what it’s like to navigate HTTP-based sites without HtmlUnit, a headless web browser written for Java programs. This browser provides a high-level interface for HTTP-based sites, making it your personal city guide for the web.
Although it might not be as user-friendly as other libraries, HtmlUnit makes up for it in its all-round capabilities. It offers comprehensive support for modern browser features, making it a great companion for effective web scraping and UI/End-to-End testing. It’s like the Swiss Army Knife of Java web scraping libraries, ready to tackle any challenge you throw at it.
WebMagic
If web scraping is a marathon, WebMagic is your seasoned running coach. This Java web scraping library is designed to handle large-scale tasks, making it perfect for the endurance race of complex web scraping tasks. With the help of a java web crawling library like WebMagic, you can tackle even the most challenging projects with ease, using its web crawler capabilities as a web scraper.
Built on the Scrapy architecture, WebMagic is built for speed and scalability. It’s like a race car, ready to tear down the track at breakneck speeds, handling high-volume tasks with ease. But bear in mind, it’s not for the faint-hearted. Its documentation might be sparse, and its API might seem awkward, but once you get the hang of it, it’s all smooth sailing.
Selenium
Web scraping can sometimes feel like trying to catch a fish with your bare hands, especially when dealing with dynamic web pages. But fear not, for Selenium is here to lend you a fishing net. This popular Java library is the perfect tool for automating web browsers and scraping dynamic web pages.
With Selenium, you gain easy control over your browser and can extract elements with the precision of a seasoned angler using css selectors. It’s like having a remote control for the web, allowing you to navigate the turbulent seas of the internet with ease and confidence.
Setting Up Your Web Scraping Environment
After selecting a Java library, the next step is to establish your web scraping environment, akin to organizing your toolbox before starting a repair task. The two main steps include selecting an Integrated Development Environment (IDE) and importing the required libraries.
Choosing an IDE
An Integrated Development Environment (IDE) is like your command center for web scraping. It’s where you write, debug, and run your code. For Java web scraping, IntelliJ IDEA and Eclipse are two command centers often chosen by developers.
IntelliJ IDEA, like a well-organized desk, offers advanced code editing and debugging capabilities. It integrates seamlessly with popular Java libraries such as Jsoup and HtmlUnit, providing a convenient API for you to write efficient web scraping scripts.
On the other hand, Eclipse is like a multi-functional workbench. It provides a dynamic environment for efficient data extraction and offers extensive library support.
Importing Libraries
Just as a toolbox is incomplete without tools, your IDE is incomplete without libraries. These libraries provide you with the functions you need to carry out your web scraping tasks. Think of them as your power tools for data extraction.
You can import libraries using Maven or Gradle, which are like your tool organizers. By specifying the libraries you need in your build file, Maven or Gradle will fetch them for you, ensuring you have all the tools you need for the job at hand.
Web Scraping Process with Java
With the command center equipped with essential tools, we can initiate the process of web crawling. The web scraping procedure with Java encompasses four steps, which you can learn in our java web scraping tutorial:
- Inspecting the target web pages
- Sending HTTP requests
- Parsing HTML content
- Storing the data we have extracted.
Inspecting Target Web Pages
Before we dive into the deep sea of web scraping, we need to know what we’re looking for. This is where inspecting target web pages comes into play. Consider it as a reconnaissance mission before the actual data extraction.
To identify the elements and attributes for data extraction, we use browser developer tools, our high-powered binoculars for the task. By examining the HTML structure of the webpage, we can chalk out a roadmap for our web scraping journey.
Sending HTTP Requests
With our roadmap ready, it’s time to hit the road. The first step of our journey is sending HTTP requests to the target web pages. This is like sending out an invitation for the data to come and join us.
Sending HTTP requests is like knocking on the door of a website, asking for information. We can use Java HttpURLConnection or third-party libraries like OkHttpClient or Jetty HttpClient to send out these invitations, also known as an http request. Once the requests are sent, we wait for the information to arrive, ready to welcome it with open arms.
Parsing HTML Content

Once the data arrives, wrapped in HTML, it’s time to extract data by parsing the HTML content. It’s like using a pair of scissors to open the package and reveal the hidden information inside.
We use Java libraries like Jsoup or HtmlCleaner to do the unwrapping. These libraries help us cut through the layers of HTML and extract the data we need. With careful precision, we navigate through the HTML structure, locating desired elements and extracting data for further processing or analysis.
Storing Extracted Data
After the unwrapping comes the sorting and storing. We take the data we’ve extracted and store it in a format that’s easy to use and analyze. This could be a CSV file, a JSON object, or a database, depending on our needs.
We use libraries like Apache Commons CSV or Gson to organize our data and store it neatly. It’s like putting away your tools after a job well done, ready for the next project. And with that, we’ve completed our web scraping mission.
Advanced Web Scraping Techniques in Java
While the basic web scraping procedure can be sufficient, we sometimes face more complex tasks. In such instances, advanced web scraping techniques are beneficial. These techniques serve as specialized tools in a spy kit, assisting us in handling more complex missions.
Multithreaded Web Scraping

If web scraping is a treasure hunt, then multithreading is like having multiple treasure hunters working together. It improves performance and efficiency by allowing us to:
- Process multiple web pages at the same time
- Reduce the time it takes to scrape large amounts of data
- Handle errors and exceptions more effectively
- Increase the overall speed of the scraping process
In Java, we can use multiple threads to run our web scraping tasks concurrently. This allows us to make multiple HTTP requests in parallel, resulting in quicker data retrieval. So, instead of waiting for one treasure hunter to finish before the next one starts, we have them all working together, speeding up the treasure hunt.
Scraping Dynamic Content
While static web pages are like open books, dynamic web pages are like locked diaries. They contain information that changes with time or in response to user actions. Scraping these dynamic web pages can be a challenge, but with the right tools, it’s a challenge we can overcome on any web page.
We can use headless browsers like HtmlUnit or Selenium WebDriver to interact with these dynamic pages. These browsers can execute the JavaScript on the pages, allowing us to access the dynamic content. With these tools, even the locked diaries of the web can be opened.
Handling Anti-Scraping Mechanisms
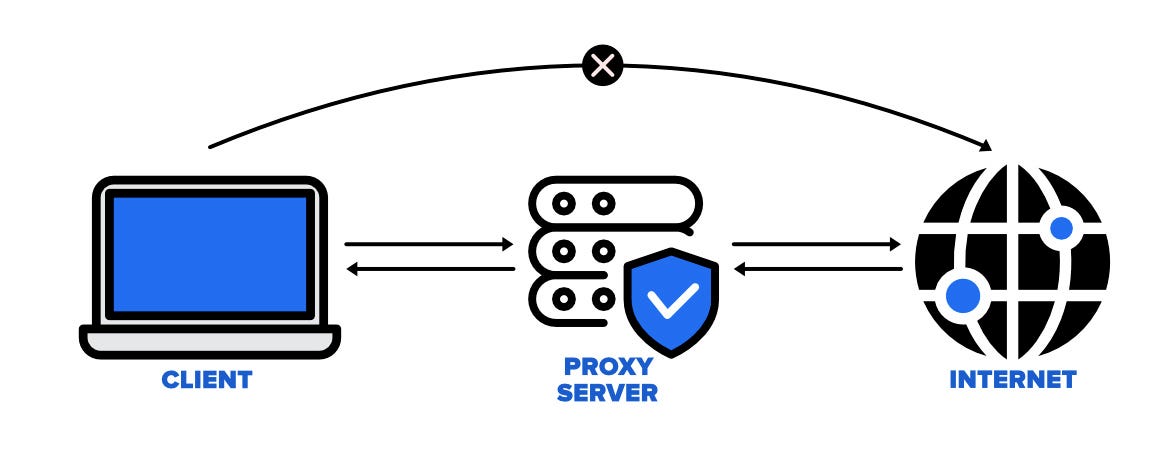
While web scraping can be a useful tool, it’s not always welcomed with open arms by websites. Some sites use anti-scraping mechanisms to protect their data. These mechanisms are like guards, blocking our path to the data.
But fear not, for we have ways to handle these guards. We can use rotating proxies, cloud-based headless browsers, or specialized libraries to bypass these security measures. With these techniques, we can navigate through the guards and access the data we need.
Best Practices for Web Scraping with Java
As with any activity, web scraping with Java has its own best practices. These guidelines act as road rules, directing us on our journey and assisting us in becoming respectful and efficient web scrapers.
First and foremost, we need to respect the website’s terms of service and robots.txt rules. Think of these as the traffic signs on our journey, guiding us on where we can go and where we can’t. We also need to implement error handling and retries, ensuring that we’re prepared for any bumps on the road.
By following these best practices, we can ensure that our web scraping project journey to scrape data is smooth and successful.
Alternatives to Java for Web Scraping
While Java is an effective tool for web scraping, it’s not the sole option available. Other languages and tools can also be utilized for web scraping, each having its own advantages and disadvantages.
Python, for example, is another popular language for web scraping. It has libraries like Beautiful Soup and Scrapy that make web scraping a breeze. There are also specialized web scraping services like Nanonets that provide a full suite of tools for web scraping, no coding required. So, whether you’re a Java enthusiast or not, there’s a tool out there for you.
Summary
Web scraping is like a treasure hunt, and Java is our trusty treasure map. With the right libraries, a well-configured environment, and a solid understanding of the process, we can navigate the vast seas of the web and unearth the data treasures hidden within. Whether it’s parsing HTML with Jsoup, automating browsers with Selenium, or handling anti-scraping mechanisms, Java equips us with the tools we need for our adventure. So get your developer’s hat on and start digging!
Frequently Asked Questions
Which library to use for web scraping?
For reliable web scraping, the popular libraries to use are Requests, BeautifulSoup, Scrapy and Selenium. Ensure that the final answer is clean of any artifacts.
Is web scraping better in Java or Python?
Overall, Python is the better language for web scraping due to its extensive library of tools and easy-to-understand syntax. Java, while powerful, is not as well-suited for web scraping as Python.
What is the R library for web scraping?
rvest is an R library for web scraping that enables users to download, parse, select, and extract data from HTML documents. With its advanced API, web scraping has become easier than ever.