Swift is a powerful programming language that allows for a myriad of possibilities, one of which is web scraping. Web scraping with Swift is a method of extracting data from websites to be used in a manner that best suits your needs. Whether you’re a seasoned developer or a novice just starting out, this blog post will guide you through the process of developing a robust web scraper using Swift libraries for web scraping.
Key Takeaways
- Unlock Swift’s potential for web scraping with increased speed, safety and ease of use.
- Choose the right library to maximize performance in relation to specific requirements.
- Leverage tools such as Xcode, CocoaPods and libraries like Alamofire & Kanna for efficient data extraction.
Unveiling Swift's Web Scraping Potential
Visualize a scenario where data isn’t confined to APIs but readily accessible and usable in all the ways you need. This is the reality of web scraping with Swift. Web scraping allows you to extract data from websites and use it in your applications. Swift, being a powerful and efficient language, makes for an excellent choice for web scraping.
Swift holds tremendous capacity for web scraping. It can be used to extract data from a page by filtering CSS selectors, reading websites, and acquiring data when APIs are not available. Swift provides access to Apple’s vast libraries and toolsets, which offer advantages for web scraping websites. However, as with any tool, it’s important to use it responsibly. Be mindful of privacy and intellectual property laws when engaging in web scraping.
It’s also essential to employ tactics and techniques to gather data in an efficient manner, ensuring your successful scraper is not blocked by the sites being studied.
Swift's Advantages in Data Extraction
Swift is more than just an elegant language. Beneath its sleek syntax lies a powerful tool that offers increased speed, improved safety, and enhanced ease of use, making it a suitable choice for cross-platform web scraping. With Swift, you can use the elements for each show located within a tag, identified by the label “Text” followed by a numerical value. This information can be used to create a web view for the extracted data. Additionally, the swift code can be an essential part of the process for seamless integration.
The regular expressions are employed to isolate only the text nodes for concerts from the HTML content, allowing users to read offline the extracted information. The parseHTML method is utilized to extract and display the text for all the shows on the page. Swift’s strong type system, performance, and interoperability with other languages make it a dependable language for data extraction, allowing developers to discover human stories from various web sources.
Choosing the Right Swift Library
Selecting the appropriate Swift library for web scraping, much like an artist picking their brush, significantly impacts the outcome of your results. SwiftSoup, Kanna, and Alamofire are popular Swift libraries for web scraping, which can be used to extract the best member-only stories from various websites. When selecting a library, it is important to assess its performance with respect to your specific use case and requirements, such as providing free distraction-free reading experiences.
For example, utilizing SwiftSoup to parse the collected data into a format the program can read is one way to use these libraries. However, there is limited information available comparing their speed and efficiency directly. It is suggested to assess their performance based on your individual use case and needs.
Setting Up Your Swift Web Scraping Environment

Before starting our Swift web scraping process, we must configure our environment. This involves installing Xcode, which is Apple’s integrated development environment (IDE) for creating apps for Mac, iPhone, iPad, Apple Watch, and Apple TV. We also need to install CocoaPods, which is a dependency manager that allows us to seamlessly add libraries to our Xcode projects.
Once we have our development environment set up, we need to add the necessary libraries to our Xcode project. These libraries provide us with the tools we need to carry out our web scraping. For our purposes, we will be using the following libraries:
- SwiftSoup: This library helps us fetch web content and parse HTML.
- Alamofire: This library helps us make HTTP requests and handle network responses.
- SwiftCSVExport: This library helps us export our extracted data to a.csv file.
By adding these libraries to our project, we will have the necessary tools to perform web scraping and extract data from websites.
Installation of Xcode and CocoaPods
The installation of Xcode and CocoaPods is an integral first step in setting up a Swift web scraping environment. Xcode is Apple’s official IDE for Swift development, and it is the primary tool for creating Swift apps. It requires a Mac running macOS 11 or later, a minimum of 4GB RAM (it is recommended to have more than 8GB), and a minimum of 8GB of free space on disk. Once Xcode is installed, the next step is to install CocoaPods.
CocoaPods is a dependency manager that makes it easy to add libraries to your Xcode projects. The purpose of CocoaPods in the starter project is to install the necessary dependencies for the project.
Adding Libraries to Your Project
After installing Xcode and CocoaPods, the next step is to add the necessary libraries to your Xcode project. These libraries will provide the functionalities needed for web scraping. For our purposes, we will need the SwiftSoup, Alamofire, and SwiftCSVExport libraries.
CocoaPods is a handy tool that makes it easy to add these libraries to an Xcode project. It is a dependency manager that facilitates the integration of third-party libraries and frameworks into Xcode projects.
Essential Swift Libraries for Web Scraping Mastery
For Swift developers delving into web scraping, several essential libraries will prove indispensable: Alamofire, Kanna, and SwiftSoup.
Some useful libraries for web development in Swift are:
- Alamofire: a Swift-based networking library that offers a straightforward and sophisticated interface for making network requests and handling responses.
- Kanna: an XML/HTML parser that facilitates the parsing and extraction of data from web pages.
- SwiftSoup: a powerful library for parsing and navigating HTML documents in Swift.
These libraries can greatly simplify the process of working with network requests and parsing HTML data in your Swift projects.
Alamofire: HTTP Networking Made Simple
Alamofire is the ‘Swiss Army Knife’ of Swift networking. This library provides a streamlined interface for network requests, making HTTP networking in Swift as easy as pie. With Alamofire, you can create HTTP requests with just a few lines of code.
It also offers various features that make it a powerful tool for web scraping, such as chainable request/response methods, JSON and Codable decoding, authentication support, and error handling.
Kanna: XML & HTML Parsing with Ease
If Alamofire is the ‘Swiss Army Knife’ of Swift networking, then Kanna is the ‘scalpel’ for precise and efficient HTML parsing. Kanna is an XML/HTML parser library for Swift that provides a simple and efficient way to parse HTML and XML documents. It offers an efficient means of extracting data from webpages and manipulating the parsed data.
SwiftSoup: Navigating HTML Documents
Last but not least, we have SwiftSoup. SwiftSoup is a library designed to facilitate web scraping in Swift. It allows for easy parsing and navigation of HTML documents, making it an indispensable tool in your web scraping toolkit.
SwiftSoup employs the SwiftSoup library to facilitate HTML parsing. This library provides a suite of application programming interfaces that can be used to parse and manipulate HTML documents.
Creating a Basic Web Scraper Using Swift
With our tools ready, we can proceed to create our initial web scraper using Swift. The process of creating a basic web scraper involves several steps. First, we need to install Xcode and CocoaPods. Xcode is the integrated development environment (IDE) provided by Apple for developing applications for its various platforms, including iOS, macOS, watchOS, and tvOS. CocoaPods, on the other hand, is a dependency manager for Swift and Objective-C Cocoa projects. It makes it easy to install, update and manage external libraries in our projects.
Once we have our development environment set up, the next step is to add the necessary libraries to our Xcode project. For web scraping, we will be using three libraries:
- Alamofire: a Swift-based HTTP networking library that provides a straightforward interface for making network requests and handling responses.
- SwiftSoup: a library that allows for easy parsing and navigation of HTML documents.
- SwiftCSVExport: a library that allows for the exporting of data to a.csv file.
Fetching Web Content with Alamofire
The first step in web scraping is fetching the web content that we want to scrape. This is where Alamofire comes into play. Alamofire is an elegant networking library written in Swift that simplifies the process of making HTTP requests and handling responses.
To make HTTP requests with Alamofire in Swift, we can use the Alamofire.request() method. This method allows us to create a DataRequest object, which represents a request. We can customize our request by adding headers, parameters, and other options. Once our request is set up, we can use the response method on the DataRequest object to handle the response from the server.
Parsing HTML with Your Chosen Library
Once we have fetched the web content, the next step is to parse the HTML content. For this, we can use either Kanna or SwiftSoup, depending on our preference. Both libraries provide robust and efficient HTML parsing capabilities, allowing us to extract the data we need from the HTML content. They provide comprehensive APIs for navigating and manipulating HTML documents, making it easy to locate and extract the data we need.
Despite their similarities, Kanna and SwiftSoup have their unique features and advantages. For instance, Kanna provides XML parsing capabilities in addition to HTML parsing, while SwiftSoup offers a more straightforward API for HTML parsing. Regardless of the library we choose, we can expect a smooth and efficient HTML parsing experience.
Storing and Managing Extracted Data
Once we have parsed the HTML content and extracted the necessary data, the next step is to store and manage the data. The way we store and manage our data largely depends on our specific needs and requirements. However, there are some best practices that we can follow to ensure that we handle our data effectively and efficiently, keeping in mind the importance of html structure.
For instance, we can use the following methods to store and manage our data:
- Arrays or dictionaries, depending on the type and structure of the data
- Storing data in a database or a file for easier access and management
- Using various data structures and algorithms to sort, filter, and search our data as necessary.
Advanced Techniques for Robust Web Scraping
After mastering Swift’s web scraping basics, we can progress to more sophisticated methods. These techniques can help us handle more complex web scraping tasks and improve the efficiency and reliability of our web scraper. One such advanced technique is handling dynamic web pages. Dynamic web pages are web pages that generate content dynamically based on user interactions or other factors. As a result, the content of these web pages can change over time, making it challenging to scrape data from them.
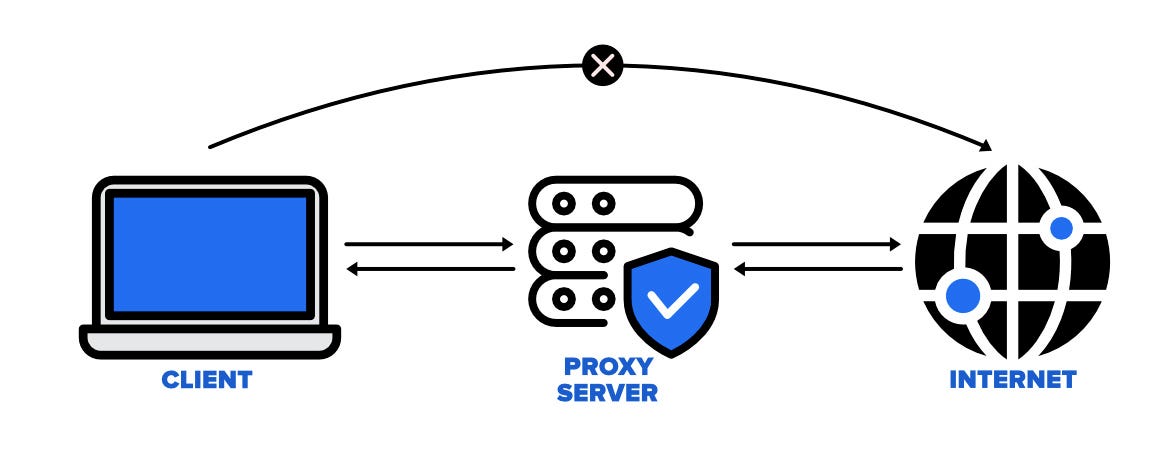
Another advanced technique is implementing rate limiting and using proxies. Rate limiting is a technique that controls the number of requests we make to a website within a specific time period. This can help us avoid overloading the server or violating the website’s terms of service.
Proxies, on the other hand, are intermediaries that we can use to send our requests to the website. By using different proxies for our requests, we can avoid getting blocked by the website due to too many requests coming from the same IP address.
Handling Dynamic Web Pages
Web scraping dynamic web pages can be a bit challenging, but it’s not impossible. These pages often rely on JavaScript to load or update their content, so we need a way to execute the JavaScript and retrieve the rendered HTML content of the web page.
One approach to this challenge is to use headless browsers. Headless browsers are web browsers without a graphical user interface. They can execute JavaScript just like regular browsers, allowing us to:
- Retrieve the rendered HTML content of dynamic web pages
- Automate tasks such as form submission and button clicks
- Take screenshots of web pages
- Perform web scraping and data extraction
Using headless browsers can be a powerful tool for web developers and testers.
We also need to consider AJAX requests, which are used by many dynamic web pages to load content asynchronously. By inspecting the network traffic, we can identify the AJAX requests and their endpoints, and then make the requests ourselves to retrieve the data.
Implementing Rate Limiting and Proxies
Implementing rate limiting and using proxies are essential techniques for robust web scraping. Rate limiting helps us control the rate at which we make requests to a website, preventing us from overloading the server or violating the website’s terms of service. There are various algorithms for implementing rate limiting, such as the token bucket algorithm, which allows us to control the rate at which we make requests by refilling a “bucket” of tokens at a specified rate.
On the other hand, proxies can help us avoid getting blocked by websites. By using different proxies for our requests, we can avoid IP-based restrictions imposed by websites, such as IP bans and rate limits.
Polishing the User Interface for Your Web Scraper App

Once our web scraper’s core functionality is established, we can turn our attention to the user interface (UI). A well-designed UI can significantly enhance the user experience, making it easier for users to interact with your app and understand the data you’ve scraped. To design a good UI, we need to consider a few key principles. First, the UI should be simple and intuitive. It should be easy for users to understand how to use your app and find what they’re looking for. Second, the UI should be responsive. It should look good and function well on a variety of devices and screen sizes.
When it comes to creating a user interface in Swift, SwiftUI is the way to go. SwiftUI is a modern, cross-platform, declarative UI framework from Apple that makes it easy to design beautiful and interactive user interfaces with less code. With SwiftUI, you can:
- Create complex UIs with just a few lines of code
- Automatically adapt the UI to different platforms and device sizes
- See your changes in real time with live preview, without having to run your app
Designing the UI with SwiftUI
Designing the UI for your web scraper app with SwiftUI is a breeze. SwiftUI’s declarative syntax makes it easy to create complex user interfaces with less code. With SwiftUI, you define what you want in your UI, and SwiftUI takes care of the rest. For instance, you can define a list of items, and SwiftUI will automatically generate a scrolling list. Similarly, you can define a text field, and SwiftUI will take care of all the details like managing the text state and dismissing the keyboard.
Furthermore, SwiftUI’s powerful composability allows you to build complex UIs from smaller, reusable components. This not only makes your code cleaner and easier to read, but also allows you to build more complex and sophisticated UIs.
Integrating Web Scraping Into the UI
Once you have designed your UI with SwiftUI, the next step is to integrate your web scraping functionality into the UI. This involves creating a function or method in your SwiftUI view that performs the web scraping operation. You can invoke this function when necessary, such as when a button is tapped or when the view appears. One way to do this is by using the “override func viewdidload” method to ensure the web scraping function is called when the view loads.
After extracting the required data, you can update the UI with the scraped data by assigning it to a SwiftUI property or using it to populate a view component, such as a list or text view. To ensure a smooth user experience, it’s important to handle errors and edge cases gracefully, such as managing network failures, dealing with changes in the website’s structure, and guaranteeing data consistency.
Real-world Applications of Swift Web Scraping
Web scraping isn’t merely an intriguing activity; it holds numerous practical applications in various fields. From market research to content aggregation and curation, web scraping can provide valuable insights and create new opportunities for businesses and individuals alike. Market research is a particularly impactful application of web scraping. By scraping data from competitor websites, customer reviews, industry news, and more, businesses can gain a wealth of information that can drive strategic decisions.
Content aggregation and curation is another major application of web scraping. By scraping articles, blog posts, news, and other content from various websites, you can create a centralized platform for users to access content from different sources. This not only saves users time and effort in finding relevant content, but also allows you to provide a curated and personalized user experience.
Market Research and Analysis
In the world of business, knowledge is power. And when it comes to gaining knowledge about the market, web scraping can be a powerful tool. By scraping data from various sources, businesses can gain a wealth of information that can drive strategic decisions. Some examples of data that can be scraped include:
- Competitor websites: Businesses can extract competitor pricing and product features to better understand their market position.
- Customer reviews: Businesses can extract customer reviews and ratings from e-commerce platforms to gain insights into customer preferences and sentiments.
- Industry news: By scraping industry news websites, businesses can stay up-to-date with the latest trends and developments in their industry.
Using web scraping to gather data from various web sites can provide businesses with valuable insights that can help them make informed decisions and stay ahead of the competition. By joining a partner program, companies can access specialized web scraping tools and resources to enhance their data collection efforts.
By leveraging the power of Swift web scraping, businesses can conduct comprehensive market research and analysis to drive strategic decisions and gain a competitive edge.
Content Aggregation and Curation
In the digital age, content is king. But with so much content out there, finding the right content can be like finding a needle in a haystack. This is where content aggregation and curation come in. By scraping articles, blog posts, news, and other content from various websites, including those of independent authors, you can create a centralized platform for users to access content from different sources. This not only saves users time and effort in finding relevant content, but also allows you to provide a curated and personalized user experience.
With Swift web scraping, you can create powerful content aggregation and curation platforms that provide users with the content they want, when they want it.
Summary
Web scraping is a powerful tool that allows us to extract data from websites for a myriad of uses. Whether you’re looking to conduct in-depth market research, create a content aggregation platform, or simply curious about the data behind a website, Swift provides an efficient and straightforward way to scrape the web. From setting up your environment with Xcode and CocoaPods, choosing the right libraries, creating a basic web scraper, handling dynamic web pages, implementing rate limiting and proxies, to designing an attractive and functional UI with SwiftUI, this blog post has covered the essentials of Swift web scraping. So, armed with this knowledge, it’s time to venture into the world of Swift web scraping and see what treasures await!
Frequently Asked Questions
Can you use Swift for web scraping?
Yes, you can use Swift for web scraping. However, to get the best results you should create a tailor-made scraping program. Writing a scraper in Swift is easy if you're already familiar with the language and the scraping process.
Which library to use for web scraping?
For web scraping, popular libraries such as Requests, BeautifulSoup, Scrapy and Selenium are recommended. To ensure accuracy, make sure the final answer does not include any unwanted artifacts.
What is the R library for web scraping?
Rvest is an R library designed for web scraping, enabling the user to extract data from HTML documents. It offers advanced web scraping functions through its API, making it a great choice for those looking to capture data from webpages.
What is the best language for web scraping?
Python is the best language for web scraping due to its vast collection of libraries and tools, like BeautifulSoup and Scrapy, making it practical and easy to use for developers of all experience levels.
What are the benefits of using Swift for web scraping?
Using Swift for web scraping offers a number of benefits, including its speed, safety and ease of use. Swift also provides strong typing and safety features to manage and process scraped data reliably.